Appearance
HA(高可用)-Hadoop集群环境搭建
一、前置准备
jdk8安装
Zookeeper集群环境搭建
二、集群规划
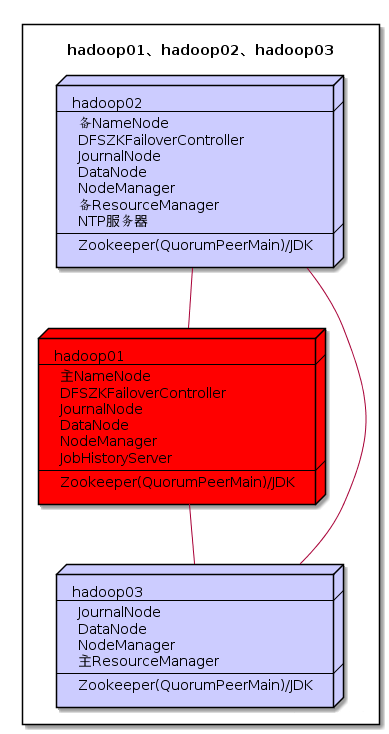
三、集群配置
先创建好所需目录
bash
$ mkdir -p /data/hadoop/tmp
$ mkdir -p /data/hadoop/dfs/journalnode_data
$ mkdir -p /data/hadoop/dfs/edits
$ mkdir -p /data/hadoop/dfs/datanode_data
$ mkdir -p /data/hadoop/dfs/namenode_data1. hadoop-env.sh
bash
export JAVA_HOME=/opt/moudle/jdk
export HADOOP_CONF_DIR=/data/hadoop/etc/hadoop2. core-site.xml
xml
<configuration>
<property>
<!--指定hadoop集群在zookeeper上注册的节点名-->
<name>fs.defaultFS</name>
<value>hdfs://hacluster</value>
</property>
<property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<name>hadoop.tmp.dir</name>
<value>file:///data/hadoop/tmp</value>
</property>
<property>
<!--设置缓存大小,默认4kb-->
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<property>
<!--指定zookeeper的存放地址 -->
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
</configuration>3. hdfs-site.xml
xml
<configuration>
<property>
<!--数据块默认大小128M-->
<name>dfs.block.size</name>
<value>134217728</value>
</property>
<property>
<!--副本数量,不配置的话默认为3-->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!--namenode节点数据(元数据)的存放位置-->
<name>dfs.name.dir</name>
<value>file:///data/hadoop/dfs/namenode_data</value>
</property>
<property>
<!--datanode节点数据(元数据)的存放位置-->
<name>dfs.data.dir</name>
<value>file:///data/hadoop/dfs/datanode_data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>4096</value>
</property>
<property>
<!--指定hadoop集群在zookeeper上注册的节点名-->
<name>dfs.nameservices</name>
<value>hacluster</value>
</property>
<property>
<!-- hacluster集群下有两个namenode,分别为nn1,nn2 -->
<name>dfs.ha.namenodes.hacluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的rpc、servicepc和http通信 -->
<property>
<name>dfs.namenode.rpc-address.hacluster.nn1</name>
<value>hadoop01:9000</value>
</property>
<property>
<name>dfs.namenode.servicepc-address.hacluster.nn1</name>
<value>hadoop01:53310</value>
</property>
<property>
<name>dfs.namenode.http-address.hacluster.nn1</name>
<value>hadoop01:50070</value>
</property>
<!-- nn2的rpc、servicepc和http通信 -->
<property>
<name>dfs.namenode.rpc-address.hacluster.nn2</name>
<value>hadoop02:9000</value>
</property>
<property>
<name>dfs.namenode.servicepc-address.hacluster.nn2</name>
<value>hadoop02:53310</value>
</property>
<property>
<name>dfs.namenode.http-address.hacluster.nn2</name>
<value>hadoop02:50070</value>
</property>
<property>
<!-- 指定namenode的元数据在JournalNode上存放的位置 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/hacluster</value>
</property>
<property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/dfs/journalnode_data</value>
</property>
<property>
<!-- namenode操作日志的存放位置 -->
<name>dfs.namenode.edits.dir</name>
<value>/data/hadoop/dfs/edits</value>
</property>
<property>
<!-- 开启namenode故障转移自动切换 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<!-- 配置失败自动切换实现方式 -->
<name>dfs.client.failover.proxy.provider.hacluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 配置隔离机制 -->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<!-- 使用隔离机制需要SSH免密登录 -->
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<!--hdfs文件操作权限,false为不验证-->
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>4. mapred-site.xml
xml
<configuration>
<property>
<!--指定mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--配置任务历史服务器地址-->
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<property>
<!--配置任务历史服务器web-UI地址-->
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<property>
<!--开启uber模式-->
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
</configuration>5. yarn-site.xml
xml
<configuration>
<property>
<!-- 开启Yarn高可用 -->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- 指定Yarn集群在zookeeper上注册的节点名 -->
<name>yarn.resourcemanager.cluster-id</name>
<value>hayarn</value>
</property>
<property>
<!-- 指定两个ResourceManager的名称 -->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<!-- 指定rm1的主机 -->
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop02</value>
</property>
<property>
<!-- 指定rm2的主机 -->
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop03</value>
</property>
<property>
<!-- 配置zookeeper的地址 -->
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<property>
<!-- 开启Yarn恢复机制 -->
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<!-- 配置执行ResourceManager恢复机制实现类 -->
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<!--指定主resourcemanager的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop03</value>
</property>
<property>
<!--NodeManager获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--开启日志聚集功能-->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!--配置日志保留7天-->
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>6. slaves
bash
hadoop01
hadoop02
hadoop03将 Hadoop 安装包分发到其他两台服务器,分发后建议在这两台服务器上也配置一下 Hadoop 的环境变量。
bash
# 将安装包分发到hadoop02
$ scp -r /data/hadoop/ root@hadoop02:/data
# 将安装包分发到hadoop03
$ scp -r /data/hadoop/ root@hadoop03:/data四、启动集群(初始化工作)
1. 启动3个Zookeeper
bash
$ zkServer.sh start
$ zkServer.sh start
$ zkServer.sh start2. 启动3个JournalNode
bash
$ hadoop-daemon.sh start journalnode
$ hadoop-daemon.sh start journalnode
$ hadoop-daemon.sh start journalnode3. 格式化NameNode
bash
【仅hadoop01】
$ hdfs namenode -format4. 复制hadoop01上的NameNode的元数据到hadoop02
bash
$ scp -r /data/hadoop/dfs/namenode_data/current/ root@hadoop02:/data/hadoop/dfs/namenode_data/5. 在NameNode节点(hadoop01或hadoop02)格式化zkfc
bash
【二者选其一即可】
$ hdfs zkfc -formatZK
或
$ hdfs zkfc -formatZK6. 在hadoop01上启动HDFS相关服务
bash
$ start-dfs.sh
Starting namenodes on [hadoop01 hadoop02]
hadoop02: starting namenode, logging to /data/hadoop/logs/hadoop-root-namenode-hadoop02.out
hadoop01: starting namenode, logging to /data/hadoop/logs/hadoop-root-namenode-hadoop01.out
hadoop03: starting datanode, logging to /data/hadoop/logs/hadoop-root-datanode-hadoop03.out
hadoop02: starting datanode, logging to /data/hadoop/logs/hadoop-root-datanode-hadoop02.out
hadoop01: starting datanode, logging to /data/hadoop/logs/hadoop-root-datanode-hadoop01.out
Starting journal nodes [hadoop01 hadoop02 hadoop03]
hadoop02: journalnode running as process 7546. Stop it first.
hadoop01: journalnode running as process 7827. Stop it first.
hadoop03: journalnode running as process 7781. Stop it first.
Starting ZK Failover Controllers on NN hosts [hadoop01 hadoop02]
hadoop01: starting zkfc, logging to /data/hadoop/logs/hadoop-root-zkfc-hadoop01.out
hadoop02: starting zkfc, logging to /data/hadoop/logs/hadoop-root-zkfc-hadoop02.out7. 在hadoop03上启动YARN相关服务
bash
$ start-yarn.sh8. 最后单独启动hadoop01的历史任务服务器和hadoop02的ResourceManager
bash
$ mr-jobhistory-daemon.sh start historyserver
$ yarn-daemon.sh start resourcemanager五、查看集群
1. jps进程查看
bash
$ jps
8227 QuorumPeerMain
8916 DataNode
8663 JournalNode
8791 NameNode
9035 DFSZKFailoverController
11048 JobHistoryServer
9147 NodeManager
9260 Jps
$ jps
7538 QuorumPeerMain
8214 NodeManager
7802 JournalNode
8010 DataNode
8122 DFSZKFailoverController
8346 ResourceManager
8395 Jps
7916 NameNode
$ jps
8897 Jps
8343 DataNode
8472 ResourceManager
8249 JournalNode
7994 QuorumPeerMain
8575 NodeManager
【查看NameNode的状态】
$ hdfs haadmin -getServiceState nn1
active
$ hdfs haadmin -getServiceState nn2
standby
【查看ResourceManager的状态】
$ yarn rmadmin -getServiceState rm1
standby
$ yarn rmadmin -getServiceState rm2
active六、集群二次启动
上面的集群初次启动涉及到一些必要初始化操作,所以过程略显繁琐。但是集群一旦搭建好后,想要再次启用它是比较方便的,步骤如下(首选需要确保 ZooKeeper 集群已经启动):
在 hadoop01 启动 HDFS,此时会启动所有与 HDFS 高可用相关的服务,包括 NameNode、DataNode 、 JournalNode和DFSZKFailoverController:
bash
$ start-dfs.sh在 hadoop03 启动 YARN:
bash
$ start-yarn.sh这个时候 hadoop02 上的 ResourceManager 服务通常还是没有启动的,需要手动启动:
bash
$ yarn-daemon.sh start resourcemanager