Appearance
关于模型文件下载
原生模型一般是safetensor格式,这种格式是本地使用python底层调用的,但由于 使用的是框架,所以要用另外一种格式,GGUF格式的模型文件
LM Studio部署
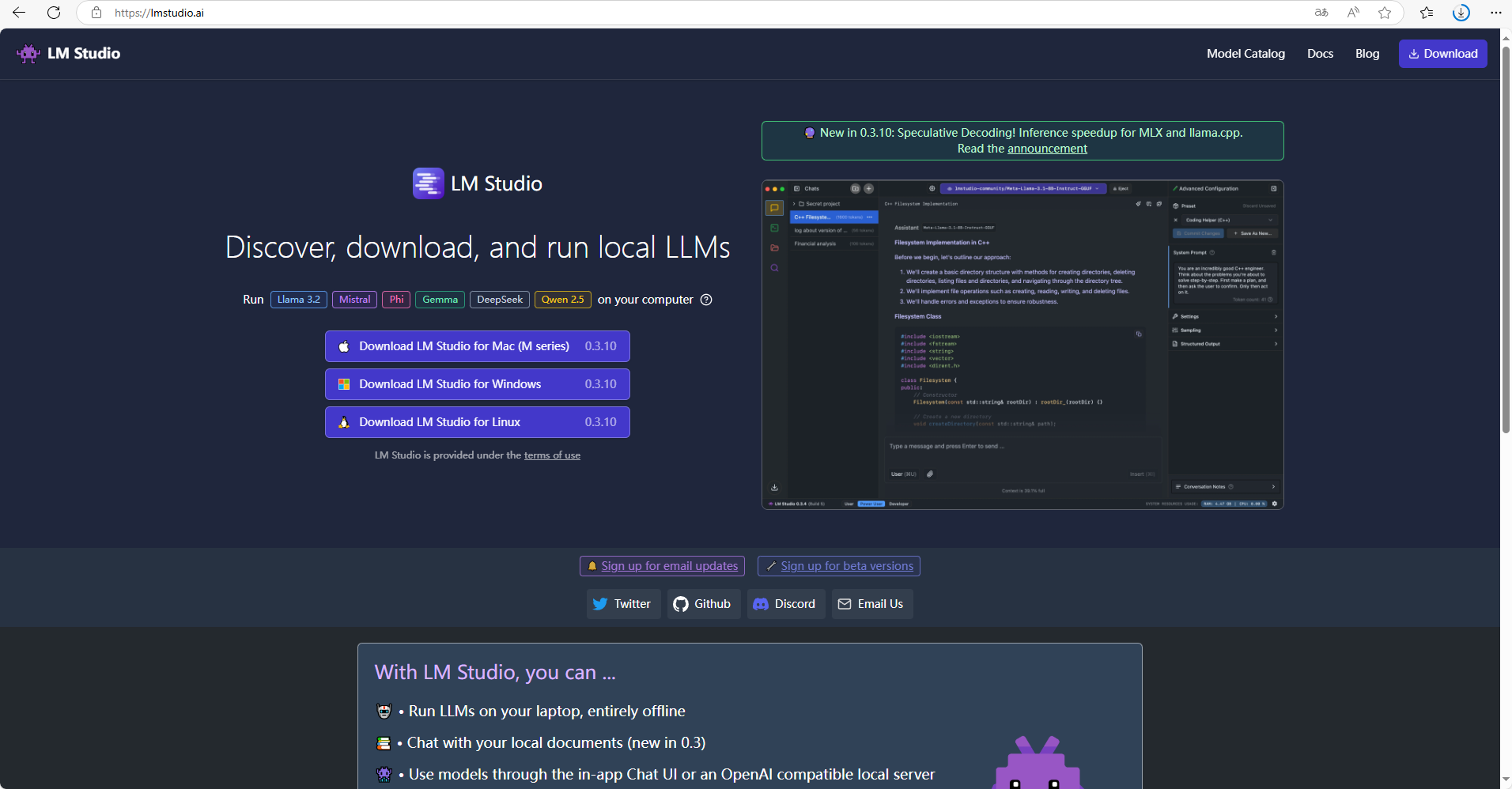
LM Studio是一款能够本地离线运行各类型大语言模型的客户端应用,通过LM Studio 可以快速搜索所需的llms类型的开源大语言模型,并进行运行。
通过使用LM Studio 在本地运行大语言模型可以更加快速的运行流畅的提问,并在独立的环境中保障数据不被监听和收集。
特点:本地、独立、离线
安装LM Studio
进入到官网后,根据自己的需要点击对于按钮即可进行下载【0.3.10 Linux目前没有ARM版本】
Windows根据提示进行安装,选择合适的目录安装即可。
安装完成打开就是这个样子
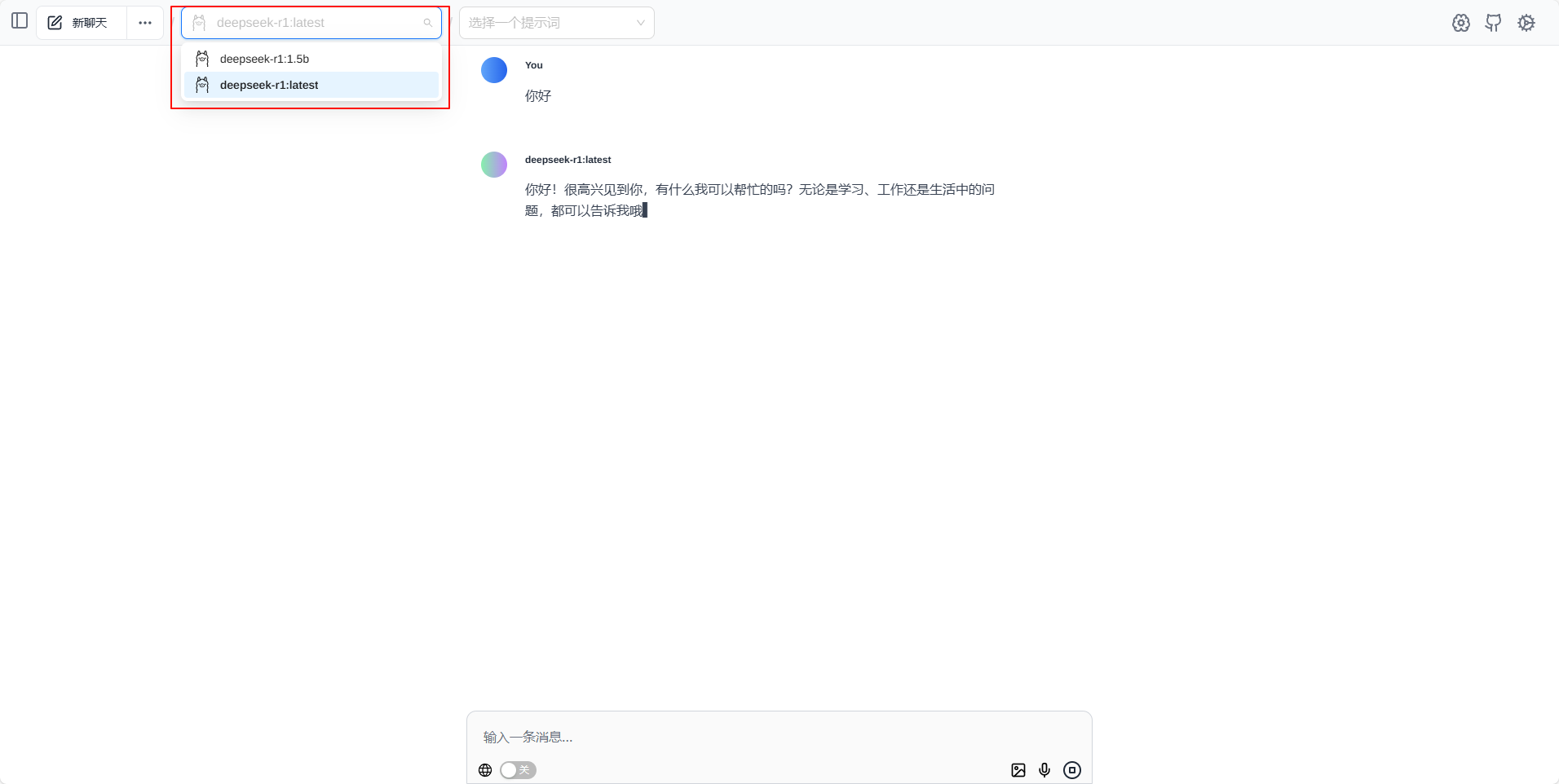
通过LM Studio 安装并本地运行DeepSeek模型
选中一个模型,这里默认可以选择LLM模型,但是也可以点击如下图的 跳过菜单进行跳过:
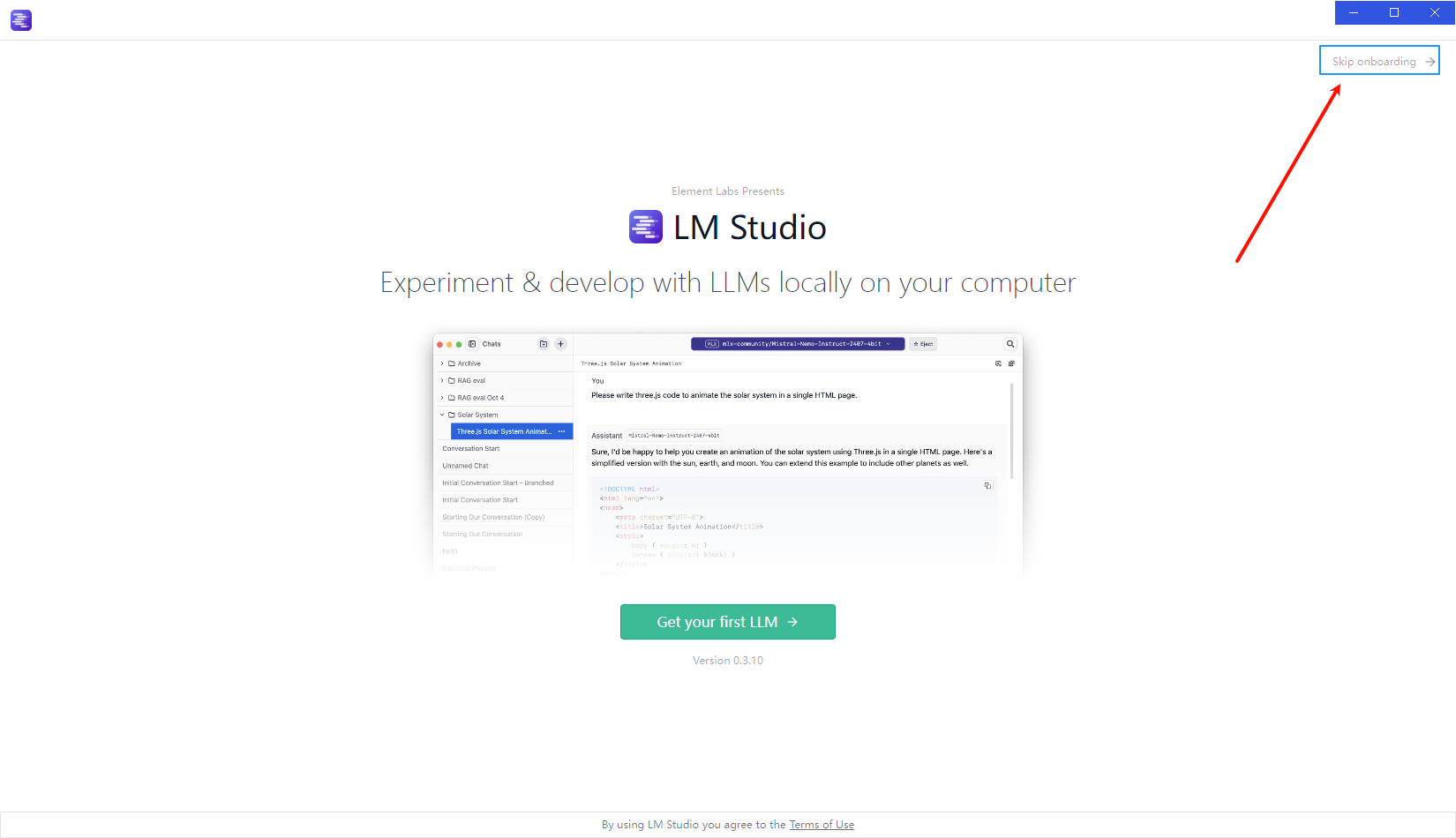
跳过后即可进入到下一环节,进入到chat界面并点击顶部的选择按钮,进行搜索和下载新的模型
搜索DeepSeek模型,如下图

点击search more …进入到检索界面,检索的信息中按照下图形式选中并点击下载即可
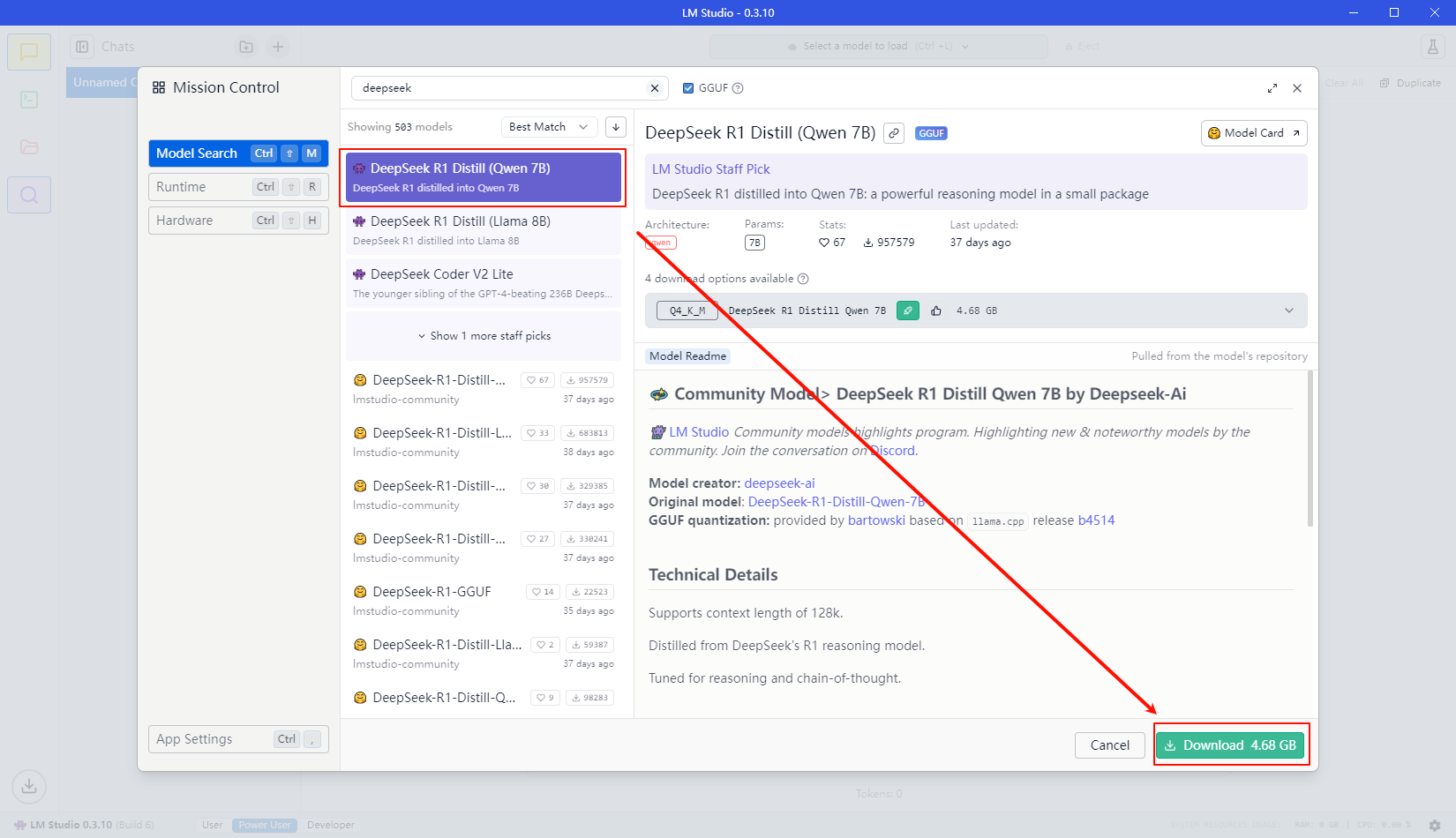
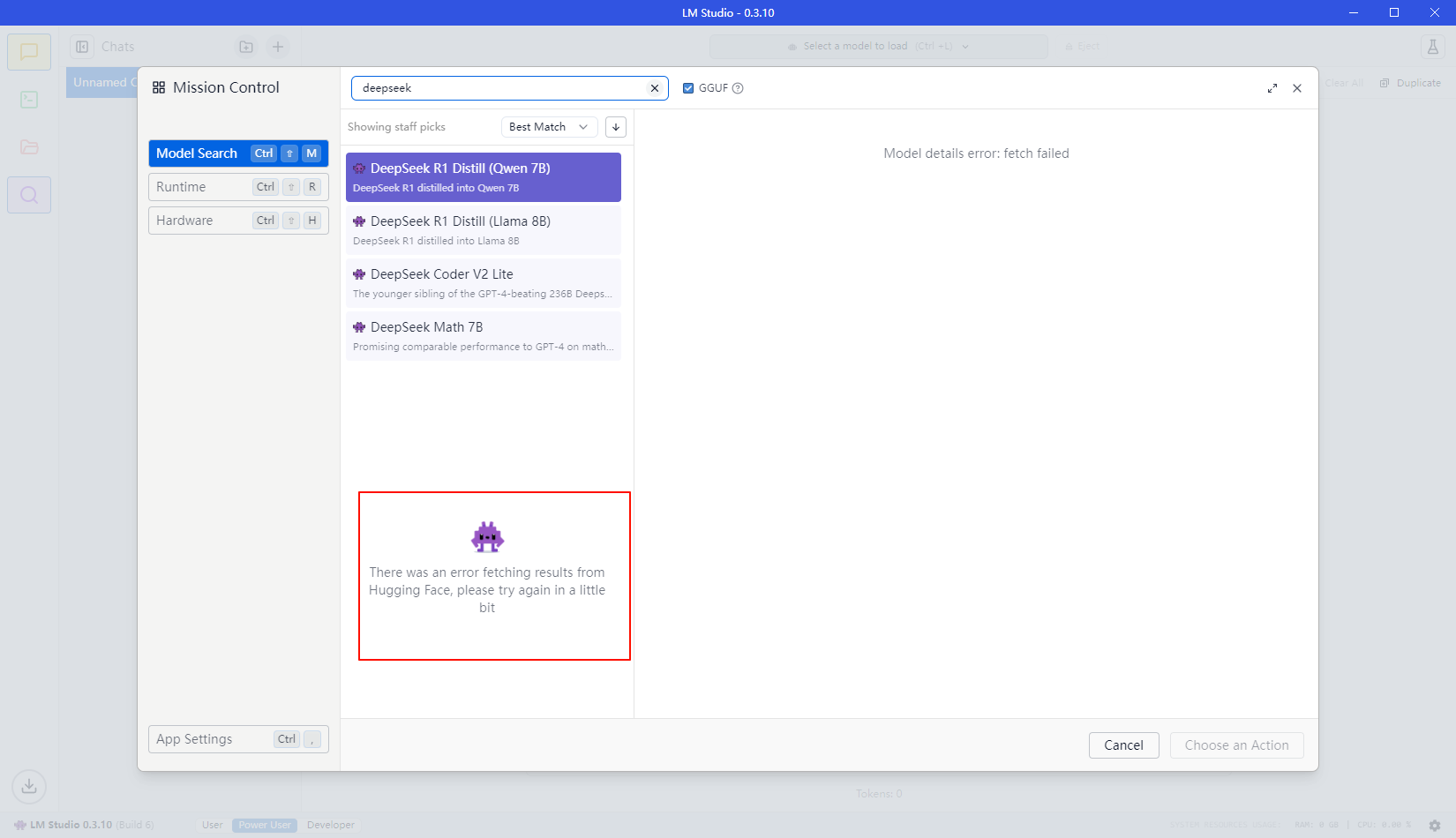
遇到“There was an error fetching results from Hugging Face, please try again in a little bit”问题
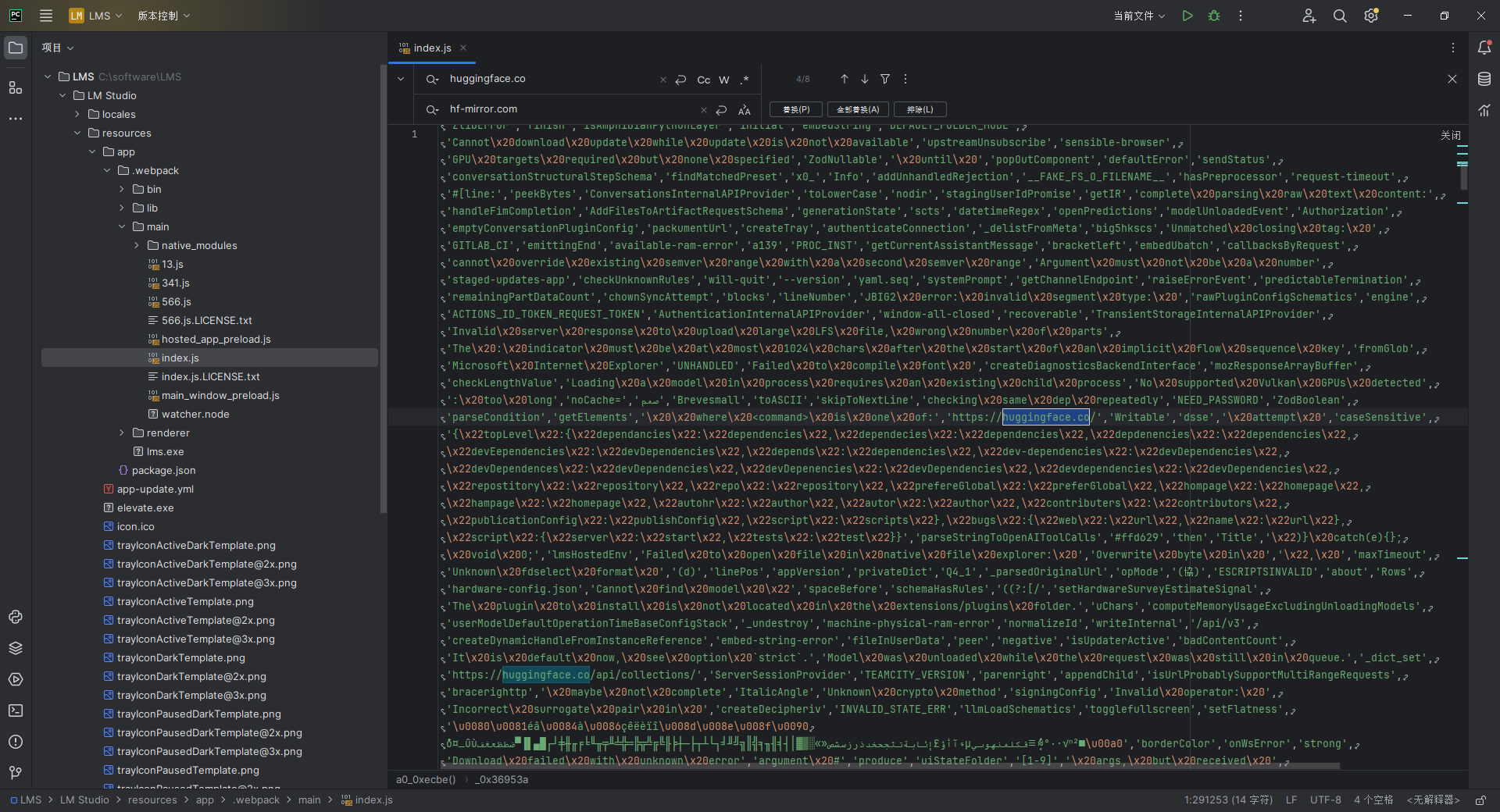
处理方法:使用VS Code或其他IDEA工具或文本编辑软件,打开安装目录下的
LM Studio/resources/app/.webpack/main/index.js文件,替换所有的huggingface.co为hf-mirror.com
然后关闭
LM Studio重新打开,再搜索下载即可
如果再不行修改
LM Studio\resources\app\.webpack\renderer\main_window.js文件,替换所有的huggingface.co为hf-mirror.com再重启尝试
等待下载完成…,下载完毕后,chat界面选择运行的模型及配置信息,如下图


点击模型,弹出配置参数表单,可以根据自己的电脑性能进行选择(性能越高,速度越快)
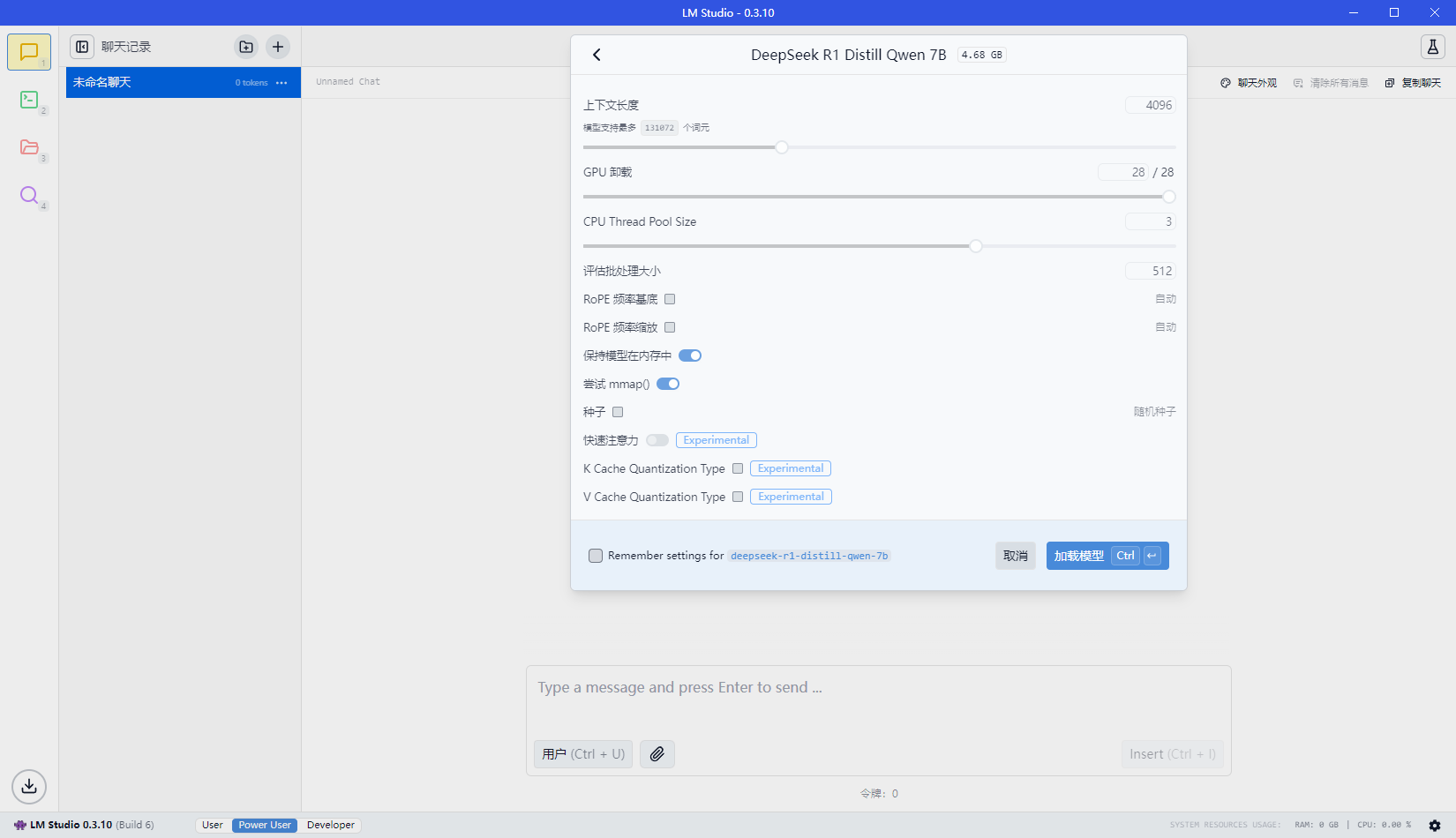
确认无误后,点击load Model即可,对于model的管理可以点击左侧的model的菜单加载进入
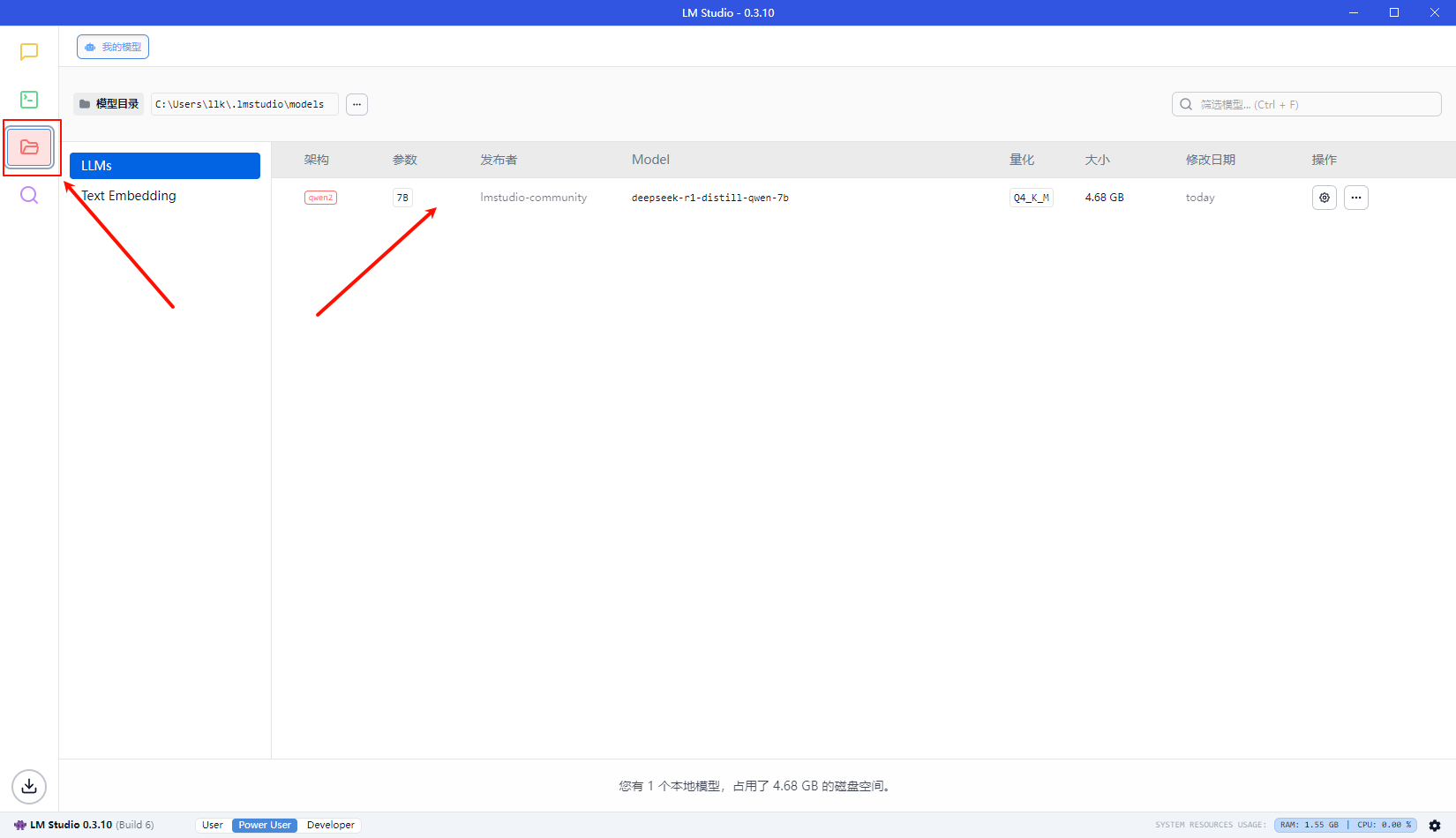
本地运行DeepSeek效果
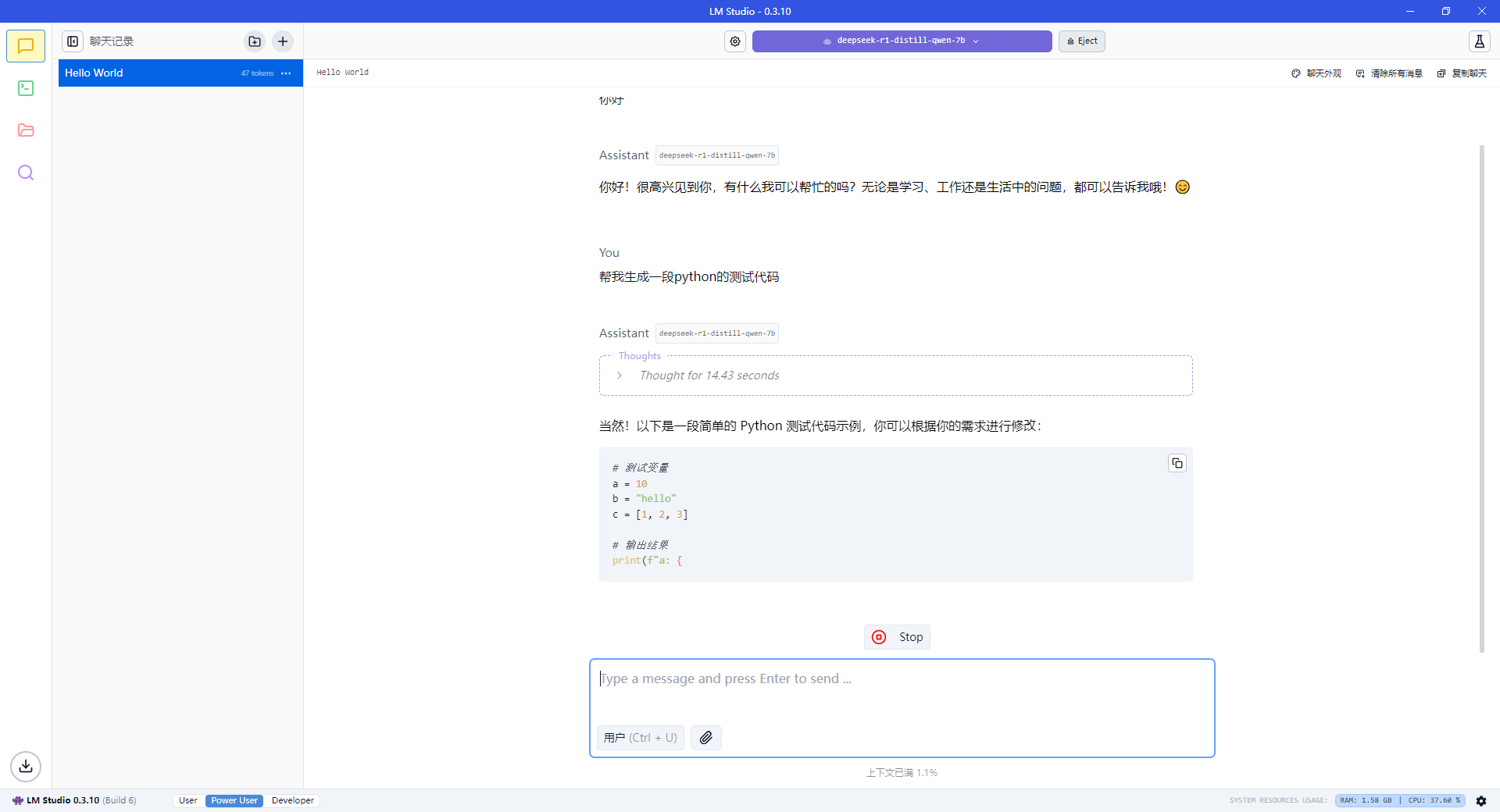
调整模型存储目录
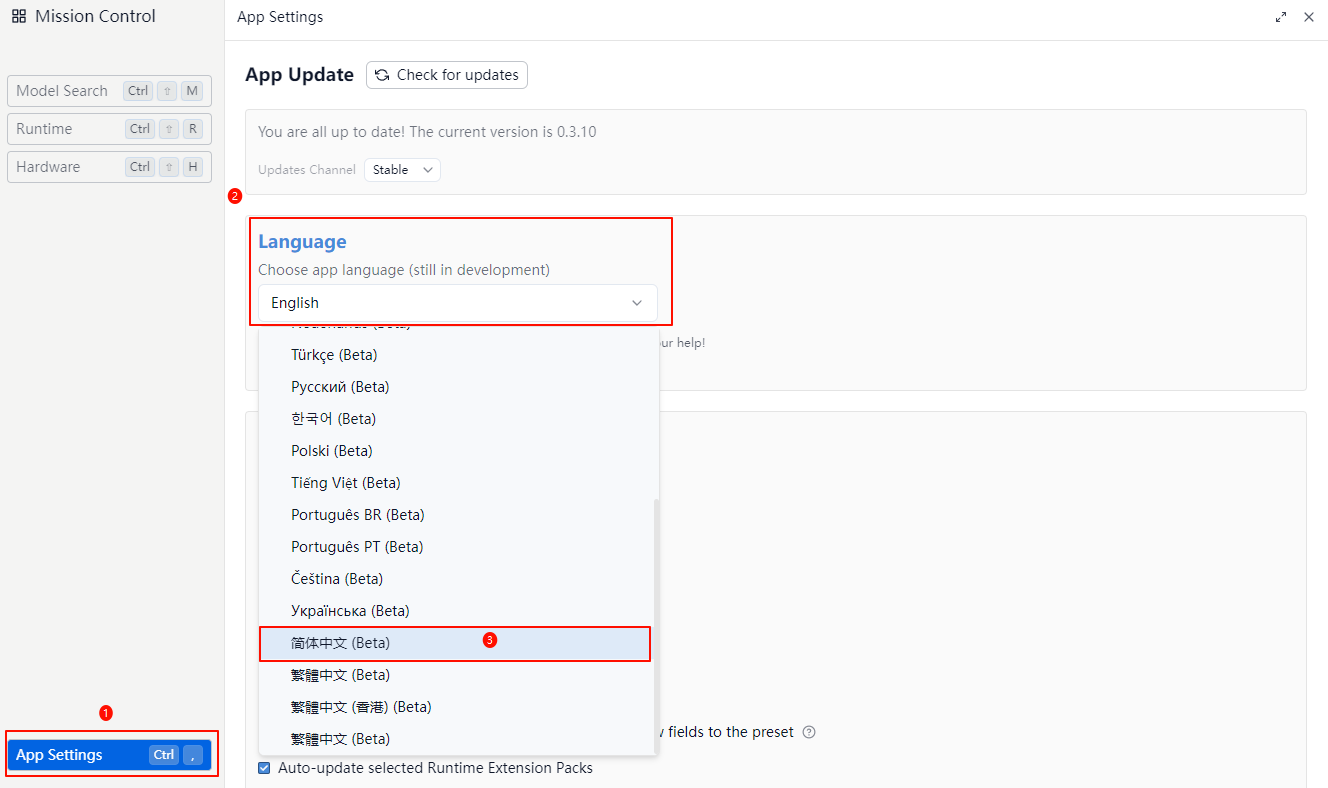
调整中文
点击 App Settings
或 点击右下角设置
在Language下选择简体中文即可
Ollama
Windows安装Ollama
点击Download,根据需要选择合适的安装包
两种安装方式:
- 通过命令安装(推荐);
- 通过鼠标双击安装(不推荐)
安装Ollama的时候,推荐使用命令【通过命令安装(推荐)】来安装,好处是可以修改安装的目录位置。
而【通过鼠标双击安装(不推荐)】是不能修改安装的目录位置的(默认安装在C盘)。
因此安装的时候强烈推荐选择【通过命令安装(推荐)】方式进行安装。
通过命令安装
之所以推荐使用命令安装,是因为通过命令安装可以修改默认的安装目录位置,而通过鼠标双击安装,默认会安装到C盘。
通常情况下不安装到C盘,此时就可以通过使用命令的方式将Ollama安装到其他盘的某个目录下。
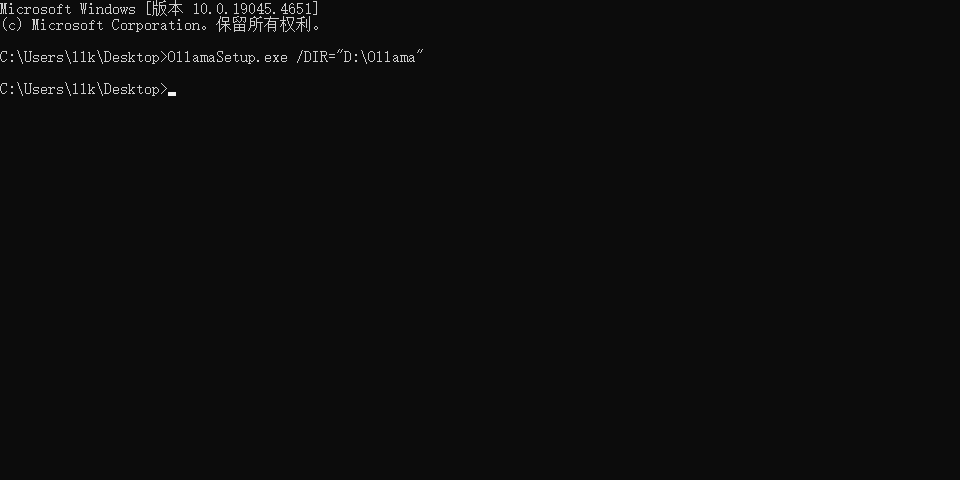
以管理员身份运行CMD,并定位到 OllamaSetup.exe 所在的目录(假设 OllamaSetup.exe 在 C:\Users\llk\Desktop 目录下),然后执行如下命令:
OllamaSetup.exe /DIR="D:\Ollama"上述命令中DIR的值为D:\Ollama,该值就是安装的目录位置。
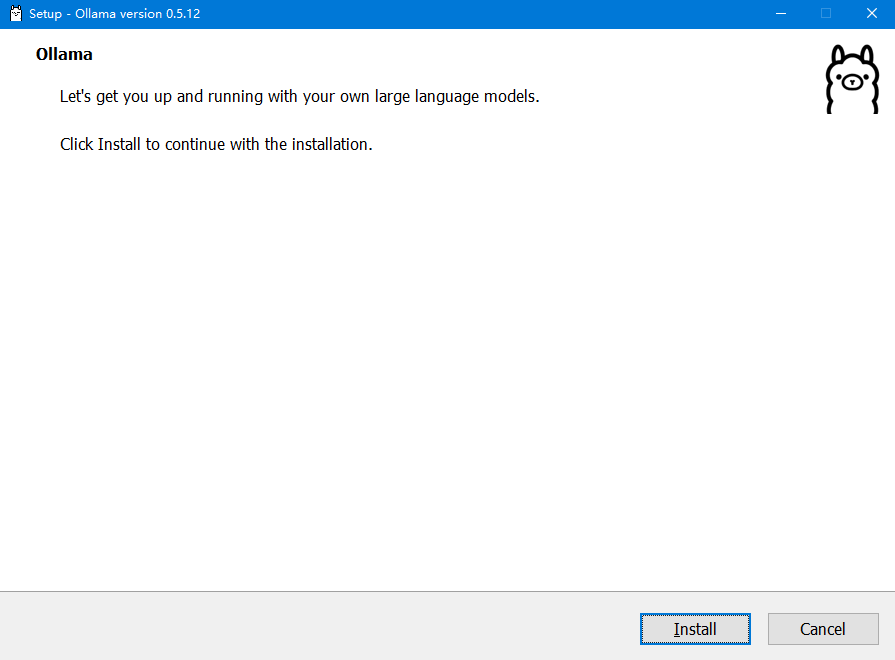
执行上述命令后,会弹出 OllamaSetup.exe 安装窗体界面,此时我们点击 Install 按钮等待安装完成即可,如下图所示:
**注意:**安装完成后,Ollama默认为打开状态,此时我们先退出Ollama(鼠标右键点击任务栏的Ollama图标然后选择退出即可)
通过鼠标双击安装
我们直接双击安装包,然后点击 Install 按钮等待安装完成即可,如下图所示:
**注意:**安装完成后,Ollama默认为打开状态,此时我们先退出Ollama(鼠标右键点击任务栏的Ollama图标然后选择退出即可)。
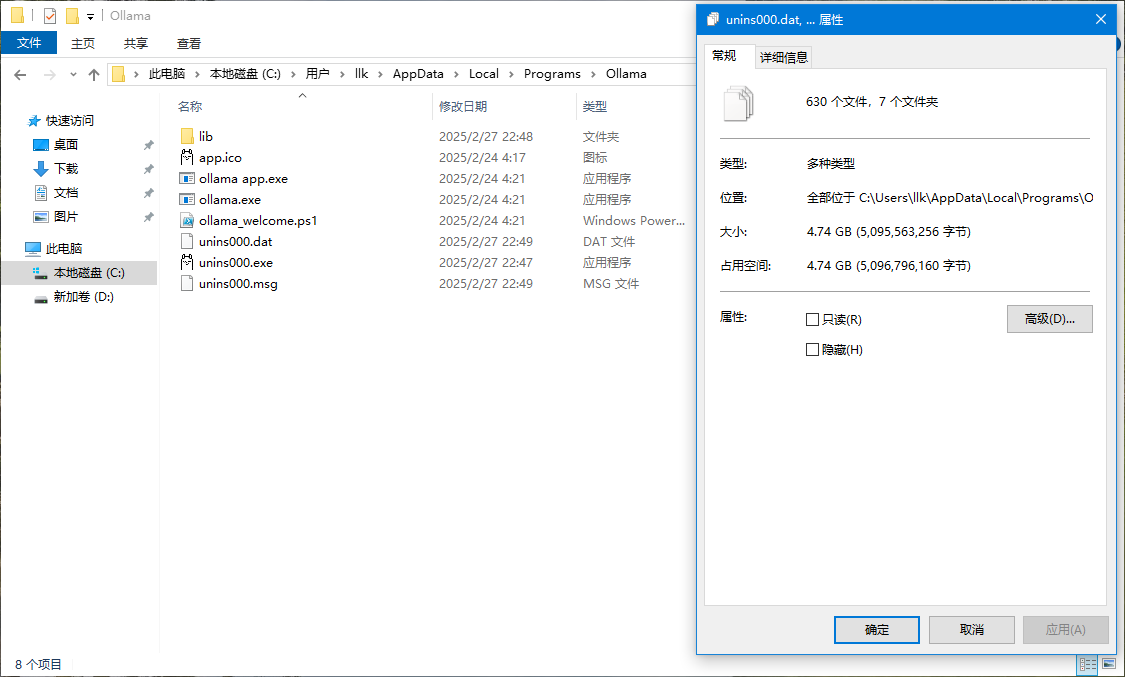
上图中,Ollama默认安装在C盘的 C:\Users\llk\AppData\Local\Programs\Ollama 目录下,如下图所示为默认安装的文件,大小大概有4.56GB:
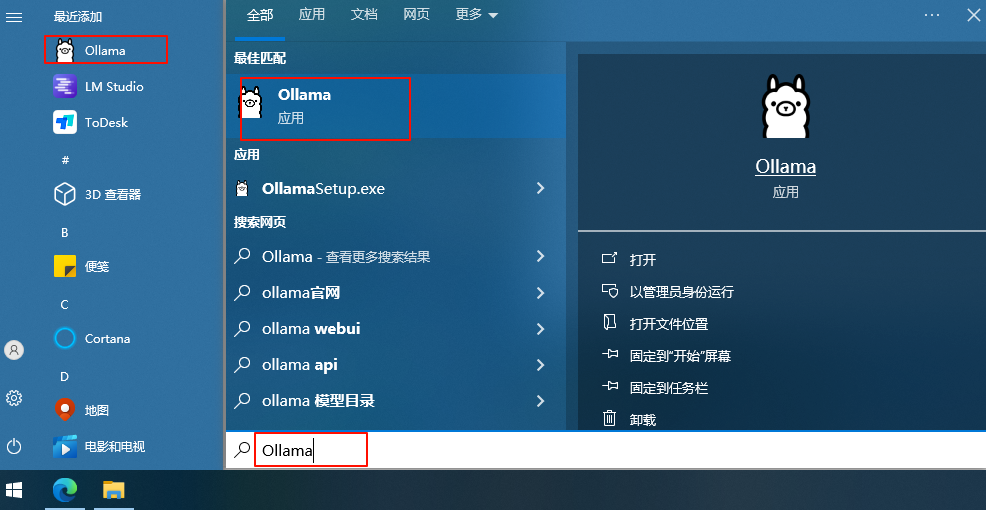
Ollama安装完成后,在桌面上是没有快捷启动图标的,我们可以在开始菜单中查找或在搜索框中搜索
转移Ollama安装目录
如果安装Ollama的时候是通过【通过命令安装(推荐)】来安装的,以下操作步骤忽略跳过即可,直接开始操作【验证Ollama】
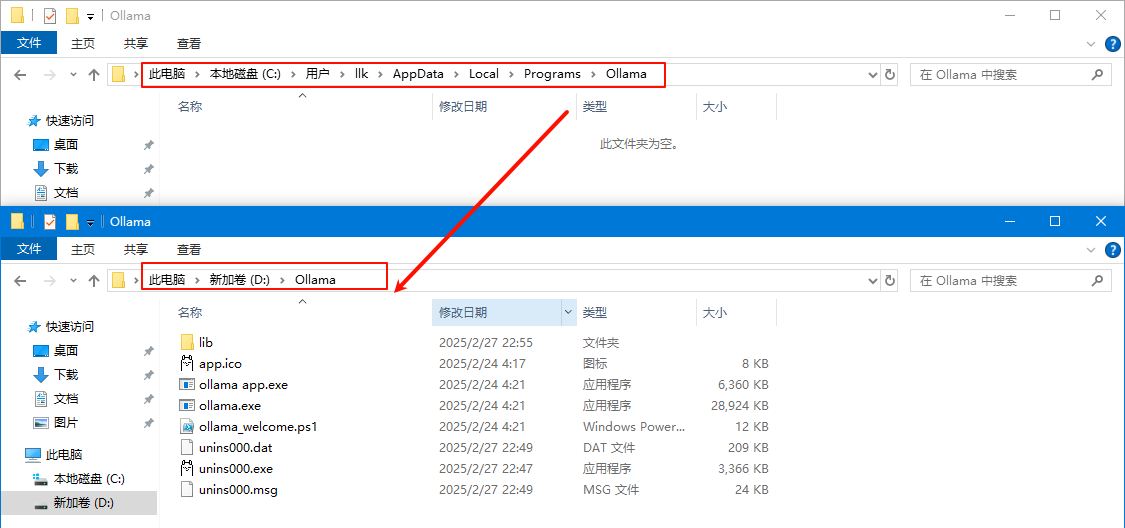
如果不想将Ollama安装到C盘,可以将安装的所有文件全部剪切到其他盘的目录内,如转移到D盘的D:\Ollama目录下,这样可以节约C盘的空间,如下图所示:
移后,我们还需要修改Ollama的环境变量。
打开环境变量,双击用户变量中的 Path ,最后一条信息就是Ollama安装完成后默认添加进来的,如下图所示:
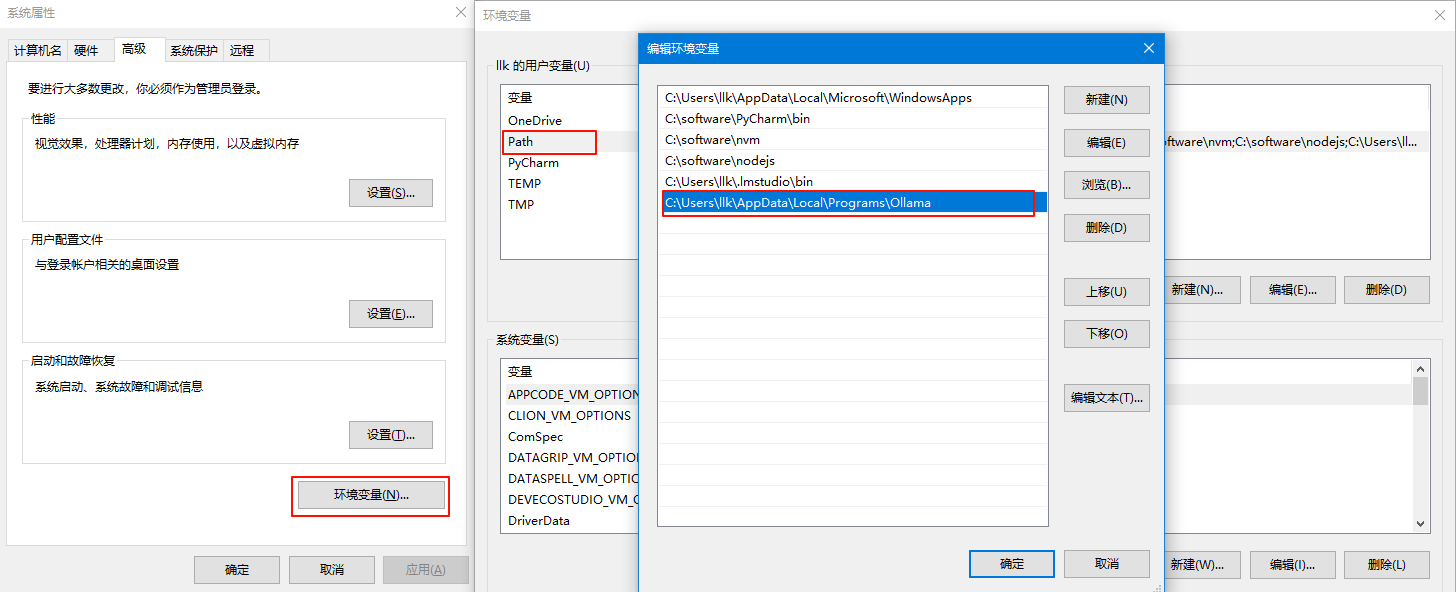
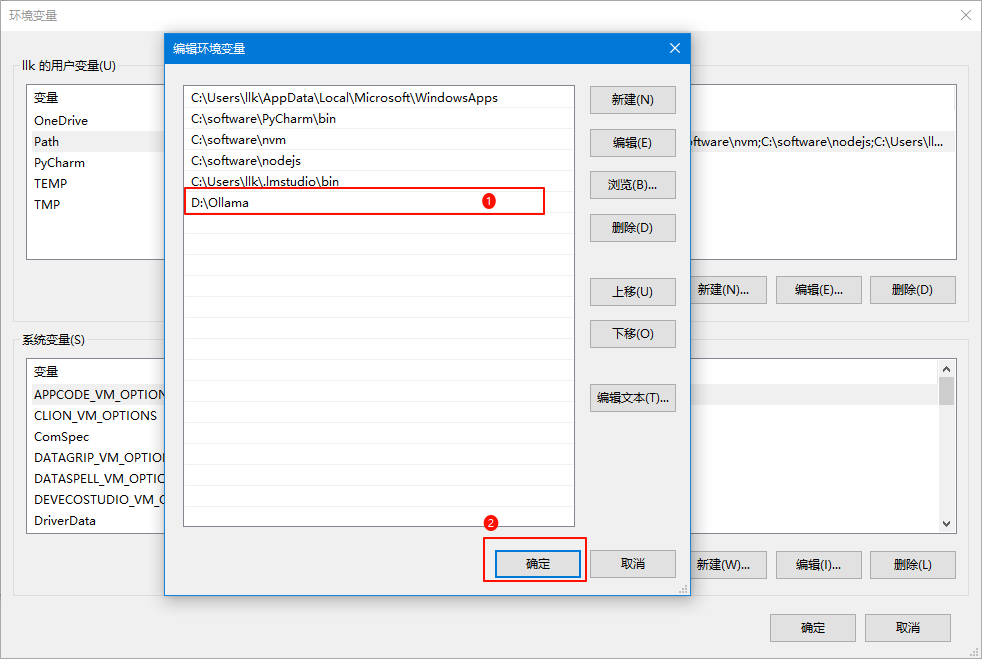
我们双击最后一条信息进入编辑状态,修改为我们转移的目录 D:\Ollama ,然后点击确定按钮关闭所有窗体即可,如下图所示
验证Ollama
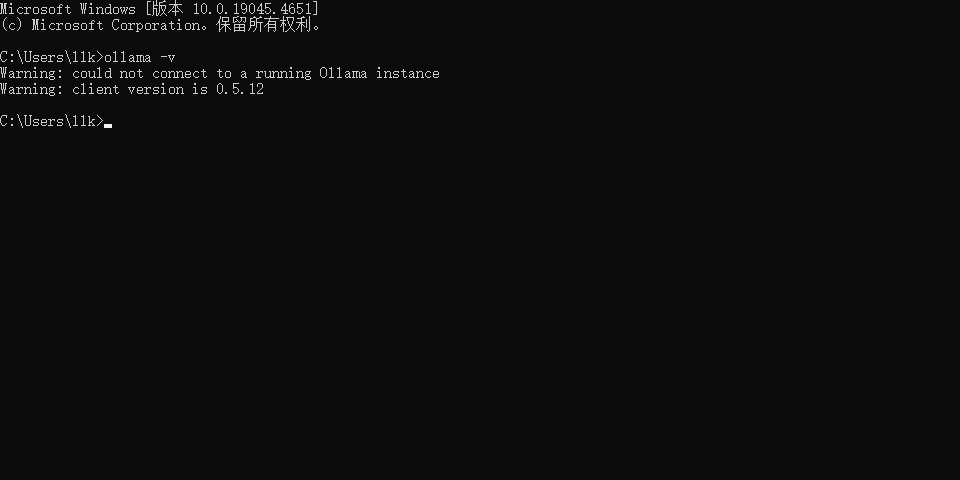
上述步骤完成后,我们可以打开CMD,输入 ollama -v 命令,如果出现如下图所示的内容就代表Ollama安装成功了:
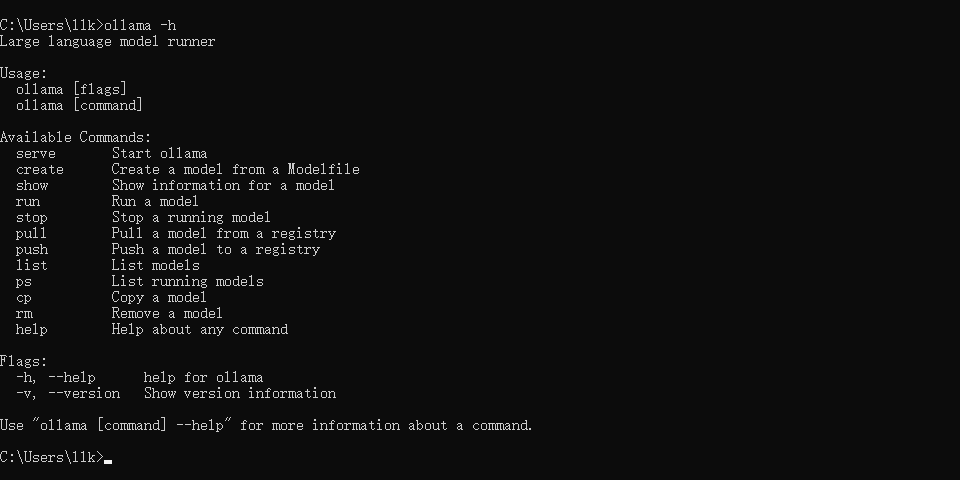
同样我们输入 ollama -h 命令可以查看Ollama其他操作命令,如下图所示
修改大模型存储位置
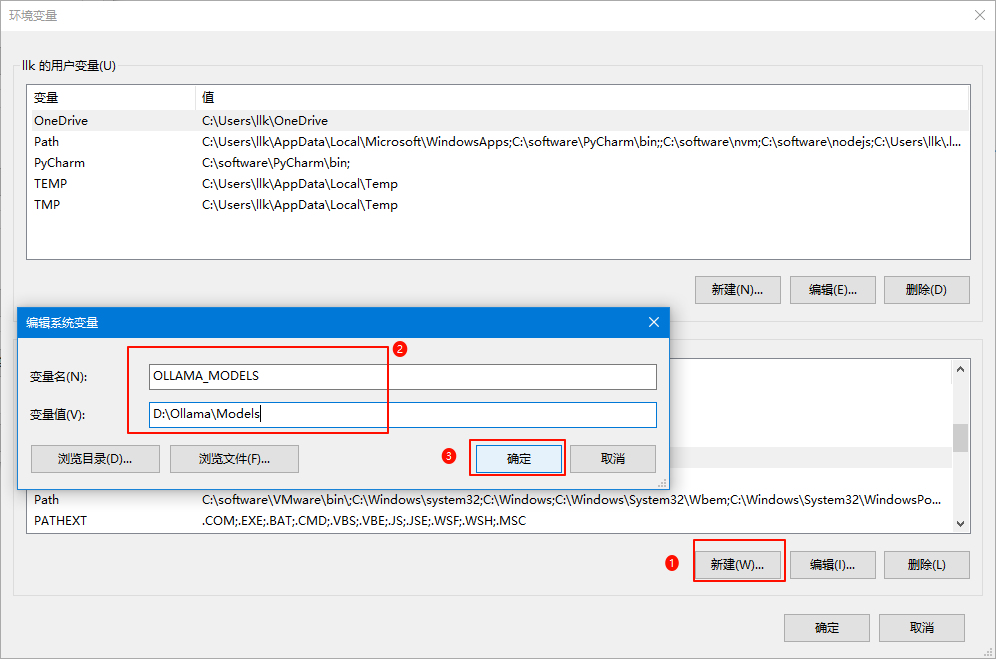
接下来需要配置大模型下载存储的目录位置(默认存储在C盘的C:\Users\llk\.ollama\models目录下)。
同样我们打开环境变量,然后在用户变量中点击新建按钮,变量名为 OLLAMA_MODELS ,变量值为 D:\Ollama\Models ,其中的变量值就是大模型下载存储的目录位置,最后点击确定即可,如下图所示:
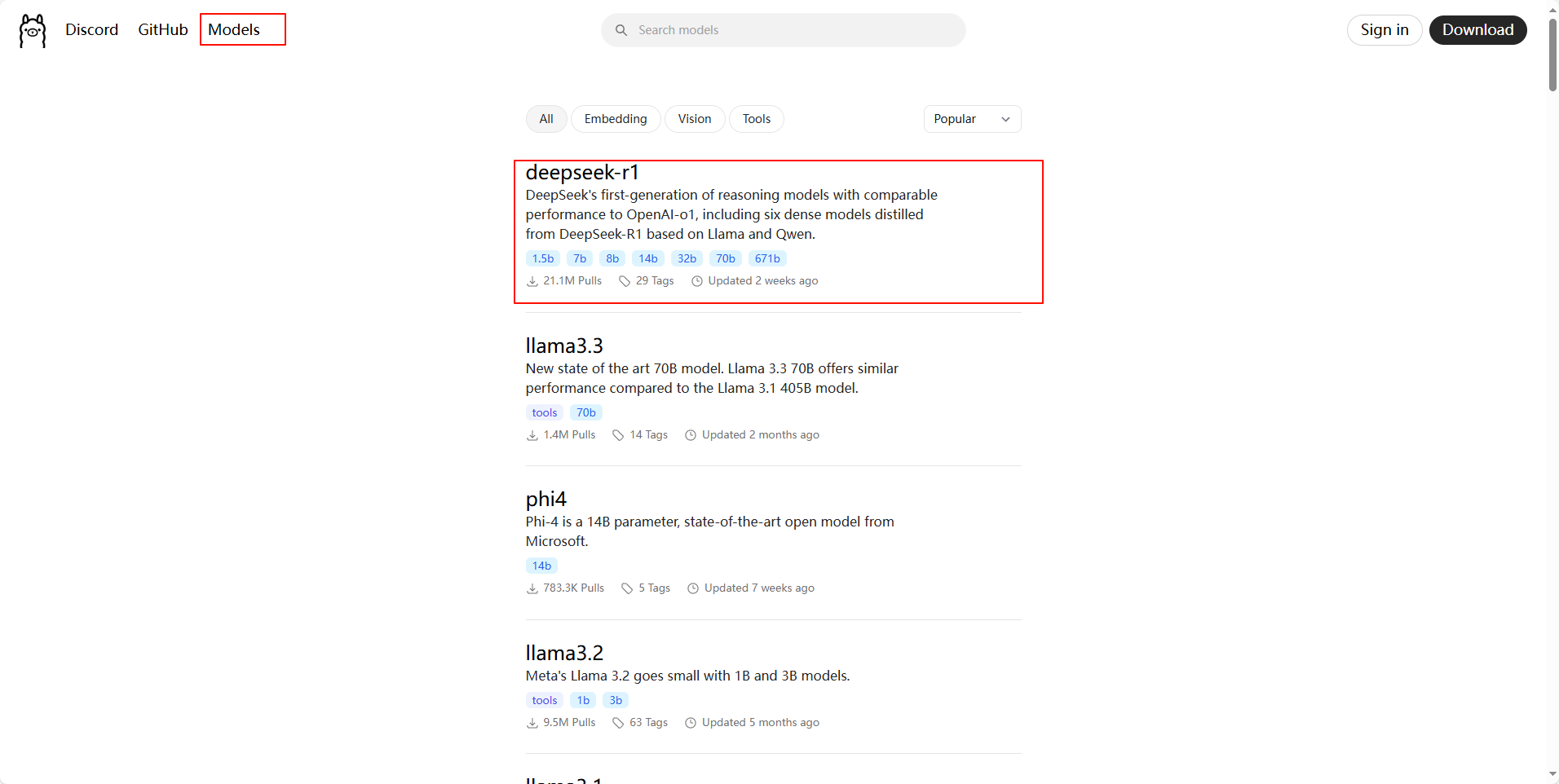
下载DeepSeek
同样我们打开 Ollama官网 ,点击顶部的 Models 链接,此时我们就会看到 deepseek-r1 模型排在第一位,如下图所示:
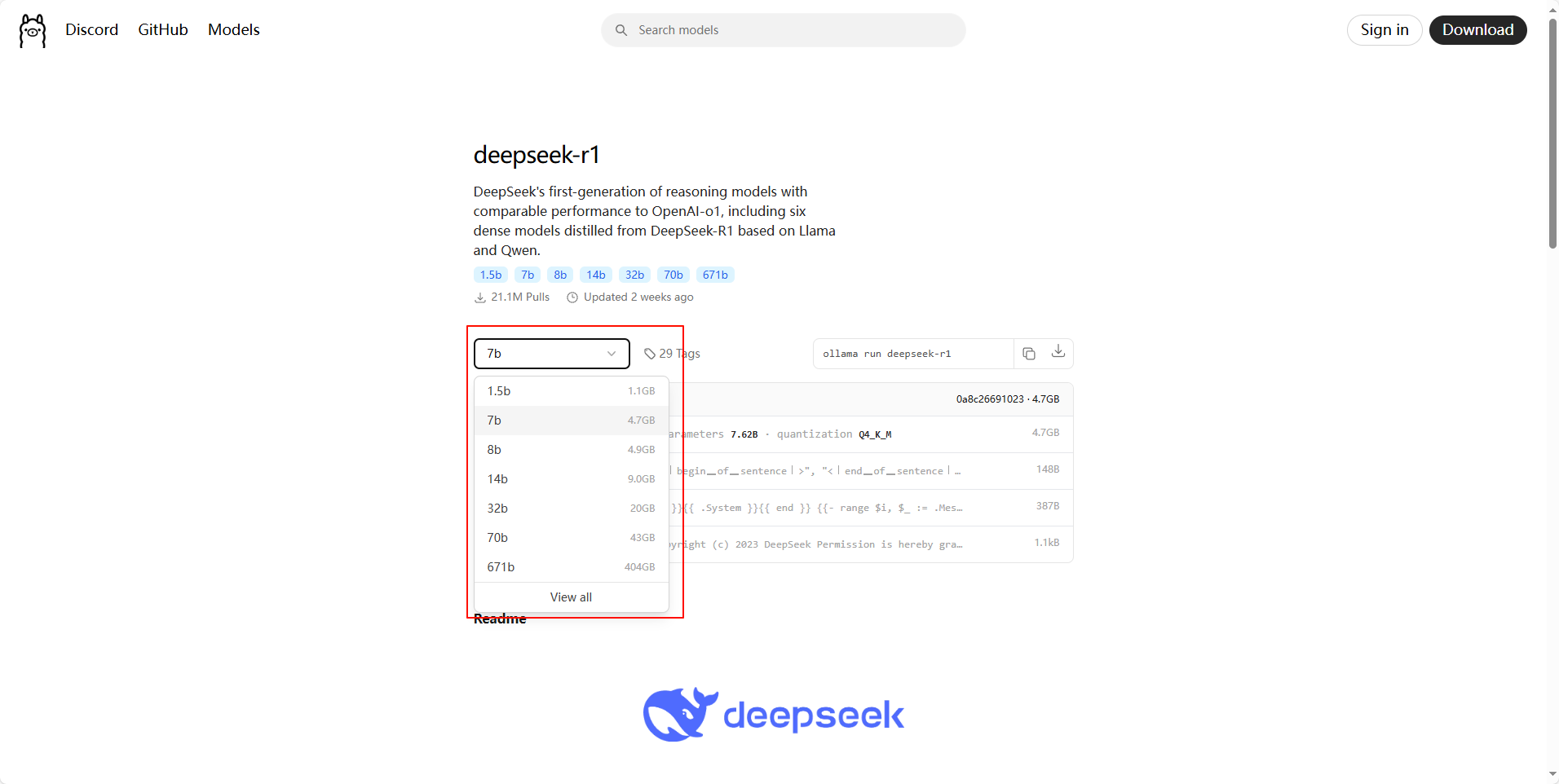
点击 deepseek-r1 链接进去,此时我们会看到下拉框中有各个版本的大模型,越往后对电脑硬件的要求越高,此处为了演示效果,我们选择1.5b进行下载(具体可根据自己的电脑和需求有选择性的下载),如下图所示:
显卡要求:
| 版本 | 要求 |
|---|---|
| DeepSeek-R1-1.5b | NVIDIA RTX 3060 12GB or higher |
| DeepSeek-R1-7b | NVIDIA RTX 3060 12GB or higher |
| DeepSeek-R1-8b | NVIDIA RTX 3060 12GB or higher |
| DeepSeek-R1-14b | NVIDIA RTX 3060 12GB or higher |
| DeepSeek-R1-32b | NVIDIA RTX 4090 24GB |
| DeepSeek-R1-70b | NVIDIA RTX 4090 24GB *2 |
| DeepSeek-R1-671b | NVIDIA A100 80GB *16 |
随后我们复制下拉框后面的命令 ollama run deepseek-r1 ,粘贴到 新打开的CMD窗口 中回车执行(耐心等待下载完成),如下图所示
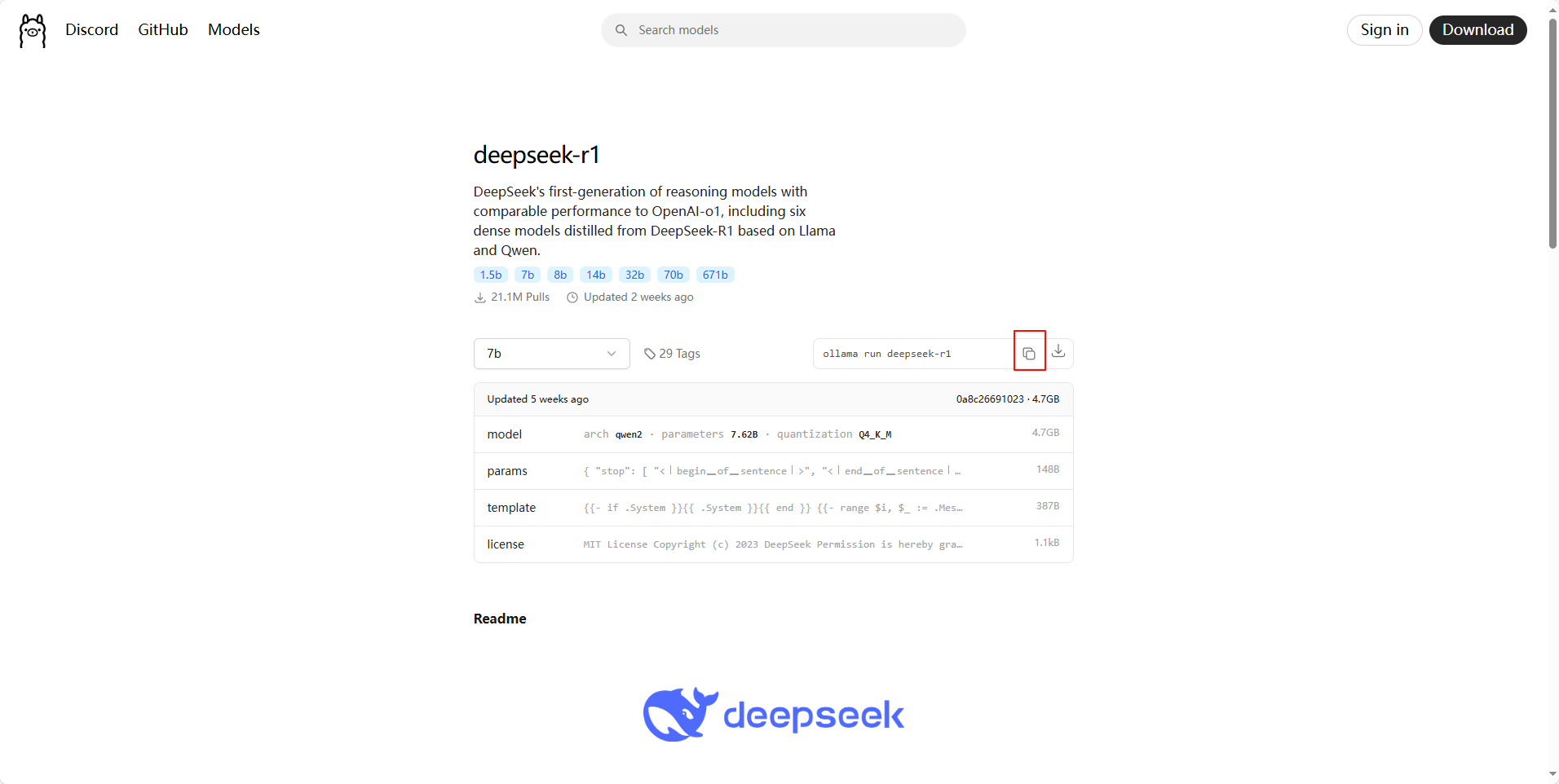
**注意:**上述下载命令需要在新打开的CMD窗口中执行(因为我们在【修改大模型存储位置】中修改了大模型存储的位置),否则下载的文件存储在C:\Users\llk\.ollama\models位置,就不是我们修改的D:\Ollama\Models这个位置了。
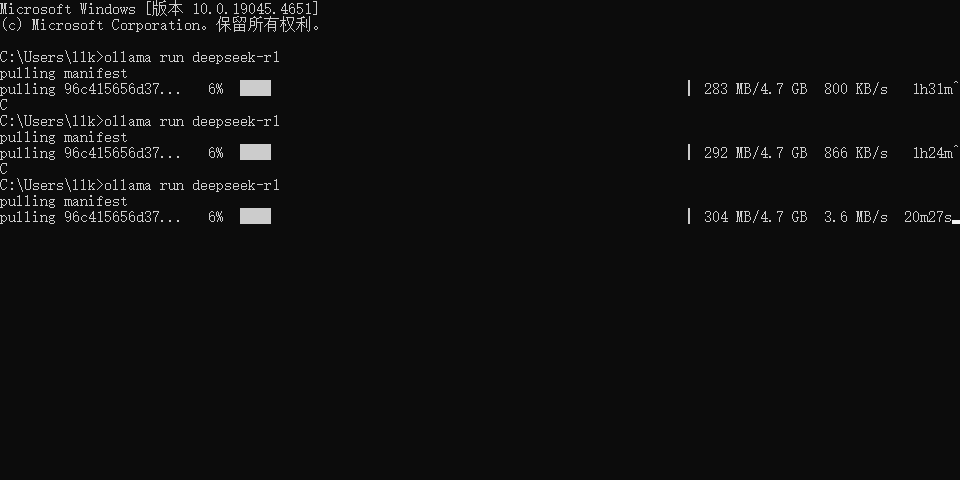
**温馨提示:**下载过程中,最开始下载速度可能要快一些,下载到后面可能就几百KB了,此时我们可以按Ctrl+C停止下载,然后再重新复制命令执行下载,此时的下载速度又恢复到了几MB了(此操作可能会遇到重新下载的情况,但是几率很小),如此往复操作即可,如下图所示:
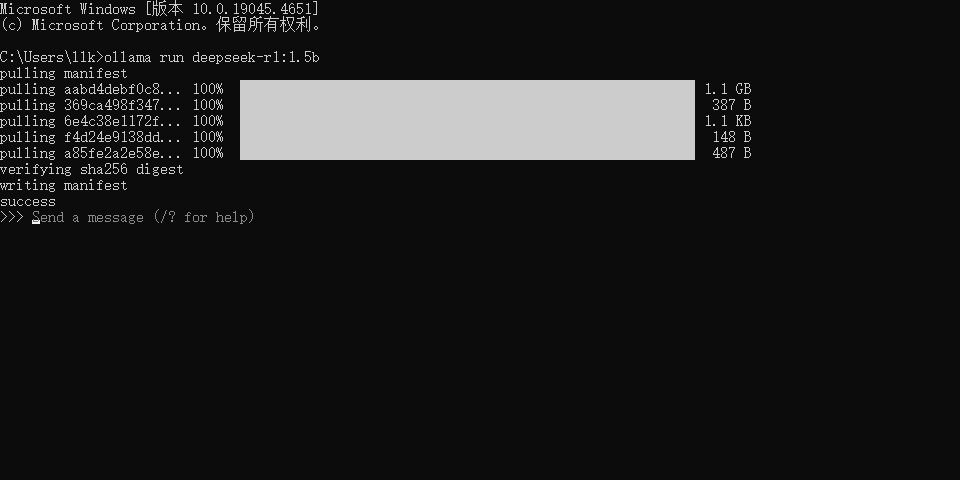
如出现如下图所示的效果就代表下载完成了:
验证DeepSeek
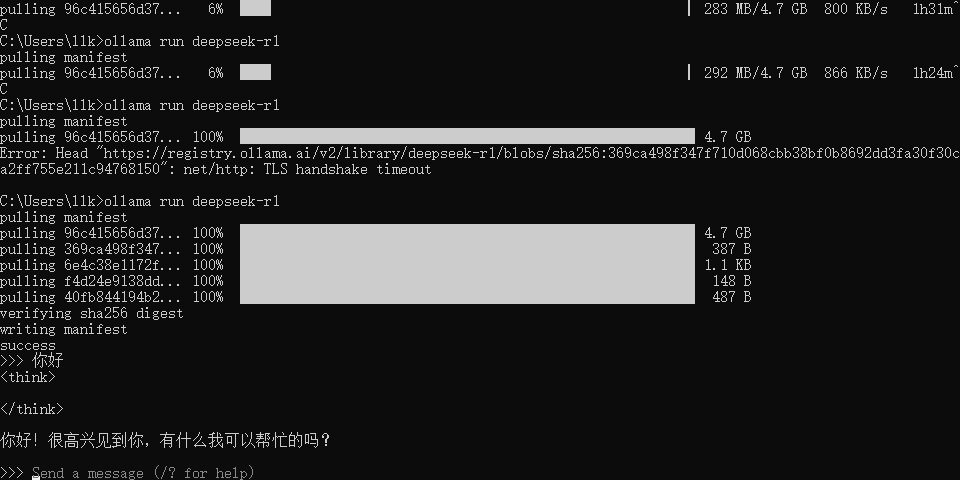
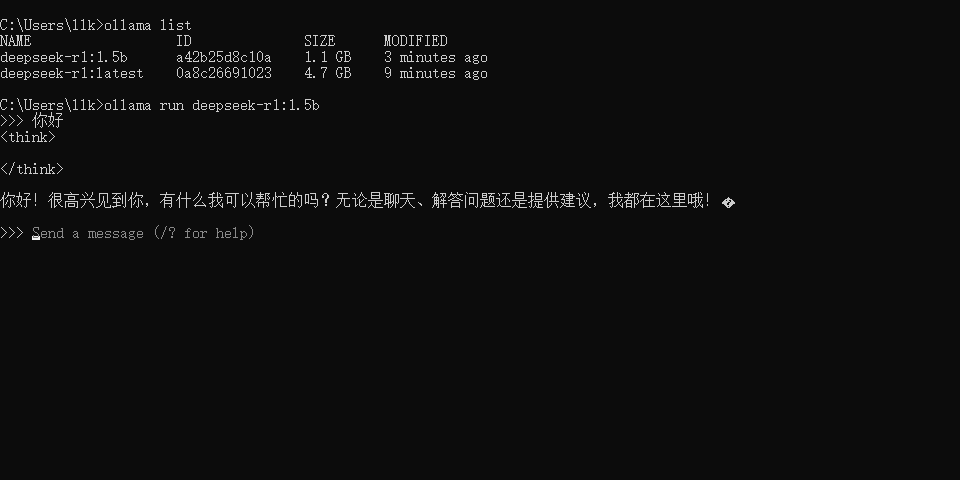
在DeepSeek下载完成后,我们就可以在CMD中输入内容进行对话了,如输入:你好,如下图所示
假设我们安装了多个DeepSeek模型,我们可以通过 ollama list 命令查看已安装了的模型,如下图所示
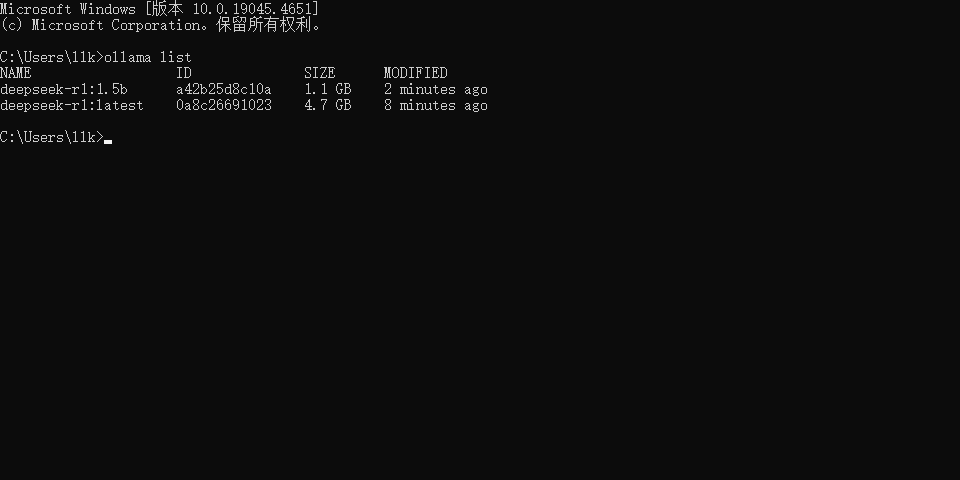
如果我们想运行某个模型,我们可以通过 ollama run 模型名称 命令运行即可,如下图所示
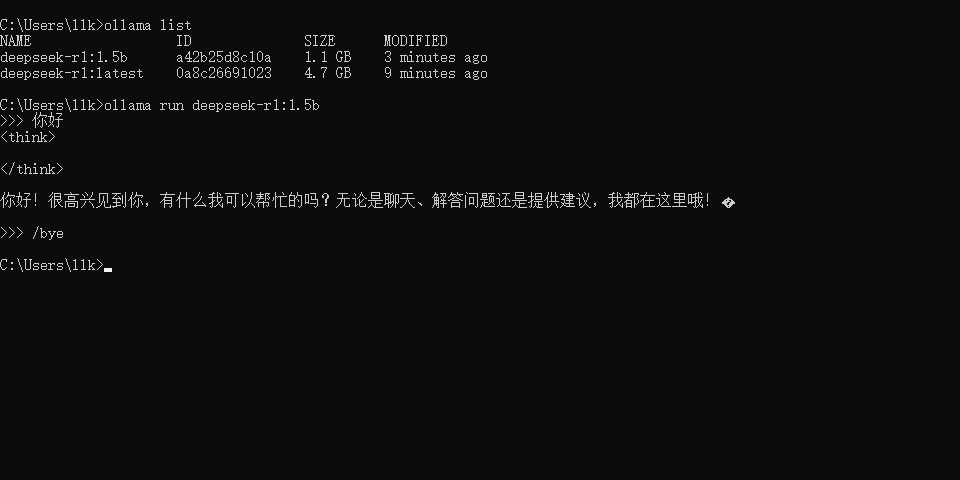
如果我们想退出对话,我们可以通过/bye命令退出,如下图所示
Linux安装Ollama
文档来自:GitHub · ollama/ollama 的文档 Ollama Linux · GitHub 并翻译
安装
要安装 Ollama,请运行以下命令:
bash
curl -fsSL https://ollama.com/install.sh | sh手动安装
注意:如果要从以前的版本升级,则应首先删除旧库
sudo rm -rf /usr/lib/ollama
下载并解压缩包:
bash
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
sudo tar -C /usr -xzf ollama-linux-amd64.tgz启动 Ollama:
bash
ollama serve在另一个终端中,验证 Ollama 是否正在运行:
bash
ollama -vAMD GPU 安装
如果您有AMD GPU,还可以下载并解压缩额外的ROCm包:
bash
curl -L https://ollama.com/download/ollama-linux-amd64-rocm.tgz -o ollama-linux-amd64-rocm.tgz
sudo tar -C /usr -xzf ollama-linux-amd64-rocm.tgzARM64 安装
下载并解压缩特定于 ARM64 的包:
bash
curl -L https://ollama.com/download/ollama-linux-arm64.tgz -o ollama-linux-arm64.tgz
sudo tar -C /usr -xzf ollama-linux-arm64.tgz将 Ollama 添加为启动服务(推荐)
为 Ollama 创建用户和组:
bash
sudo useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama
sudo usermod -a -G ollama $(whoami)创建服务文件 :/etc/systemd/system/ollama.service
shell
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"
[Install]
WantedBy=multi-user.target然后启动服务:
bash
sudo systemctl daemon-reload
sudo systemctl enable ollama安装 CUDA 驱动程序(可选)
下载并安装 CUDA 的 CUDA 中。
通过运行以下命令验证驱动程序是否已安装,该命令应打印有关 GPU 的详细信息:
bash
nvidia-smi安装 AMD ROCm 驱动程序(可选)
下载并安装 ROCm v6 的。
启动 Ollama
启动 Ollama 并验证它是否正在运行:
bash
sudo systemctl start ollama
sudo systemctl status ollama注意:
虽然AMD已将驱动程序上游提供给官方的linux内核源代码,但该版本较旧,可能不支持所有ROCm功能。
建议安装最新的驱动程序https://www.amd.com/en/support/linux-drivers为Radeon GPU提供最佳支持
amdgpu
定制
要自定义 Ollama 的安装,可以通过运行以下命令来编辑 systemd 服务文件或环境变量:
bash
sudo systemctl edit ollama或者,在 中手动创建覆盖文件 :/etc/systemd/system/ollama.service.d/override.conf
bash
[Service]
Environment="OLLAMA_DEBUG=1"更新
通过再次运行安装脚本来更新 Ollama:
bash
curl -fsSL https://ollama.com/install.sh | sh或者通过重新下载 Ollama:
bash
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
sudo tar -C /usr -xzf ollama-linux-amd64.tgz安装特定版本
在安装脚本中使用 environment variable 来安装特定版本的 Ollama,包括预发行版。可以在 releases 页面中找到版本号。OLLAMA_VERSION
例如:
bash
curl -fsSL https://ollama.com/install.sh | OLLAMA_VERSION=0.5.7 sh查看日志
要查看作为启动服务运行的 Ollama 的日志,请运行:
bash
journalctl -e -u ollama卸载
删除 ollama 服务:
bash
sudo systemctl stop ollama
sudo systemctl disable ollama
sudo rm /etc/systemd/system/ollama.service从bin目录中删除ollama二进制文件(/usr/local/bin、/usr/bin、/bin):
bash
sudo rm $(which ollama)删除下载的模型以及 Ollama 服务用户和组:
bash
sudo rm -r /usr/share/ollama
sudo userdel ollama
sudo groupdel ollama删除已安装的库:
bash
sudo rm -rf /usr/local/lib/ollamaPage Assist可视化
获取 Page Assist
下载地址: Page Assist - 本地 AI 模型的 Web UI
点击 安装到浏览器
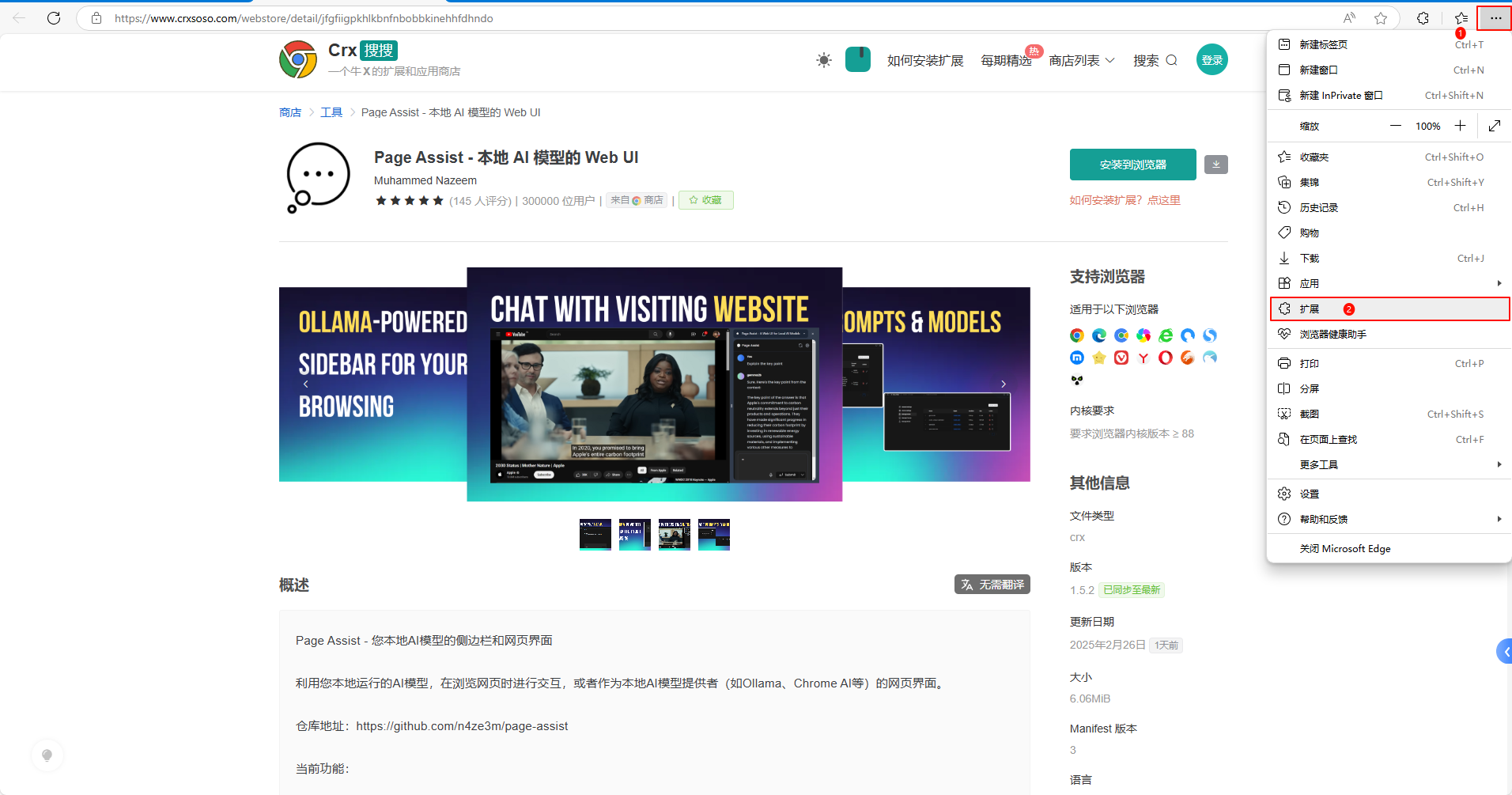
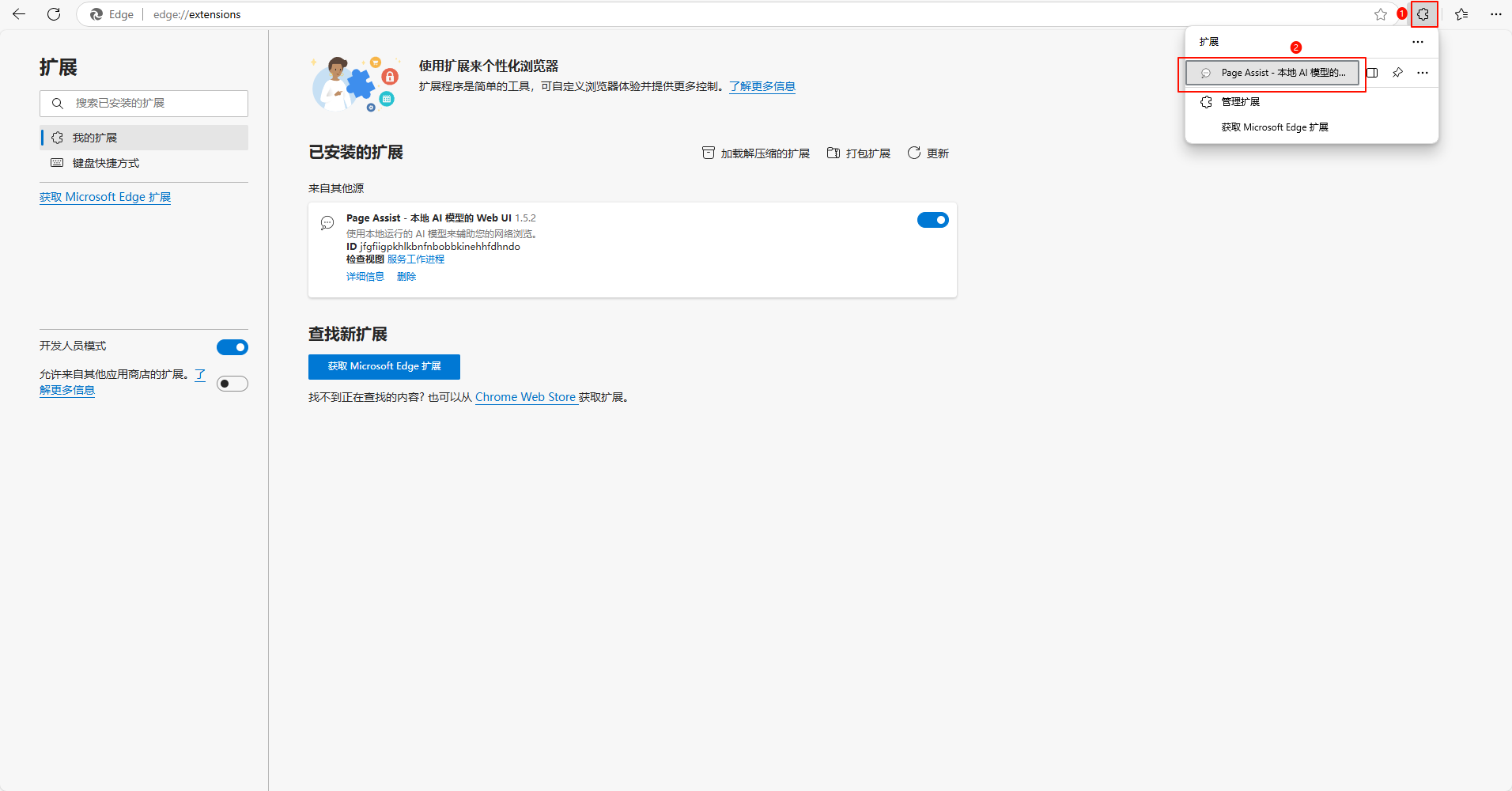
以Edge浏览器为例,点击菜单——>扩展——>扩展管理,打开开发人员选项
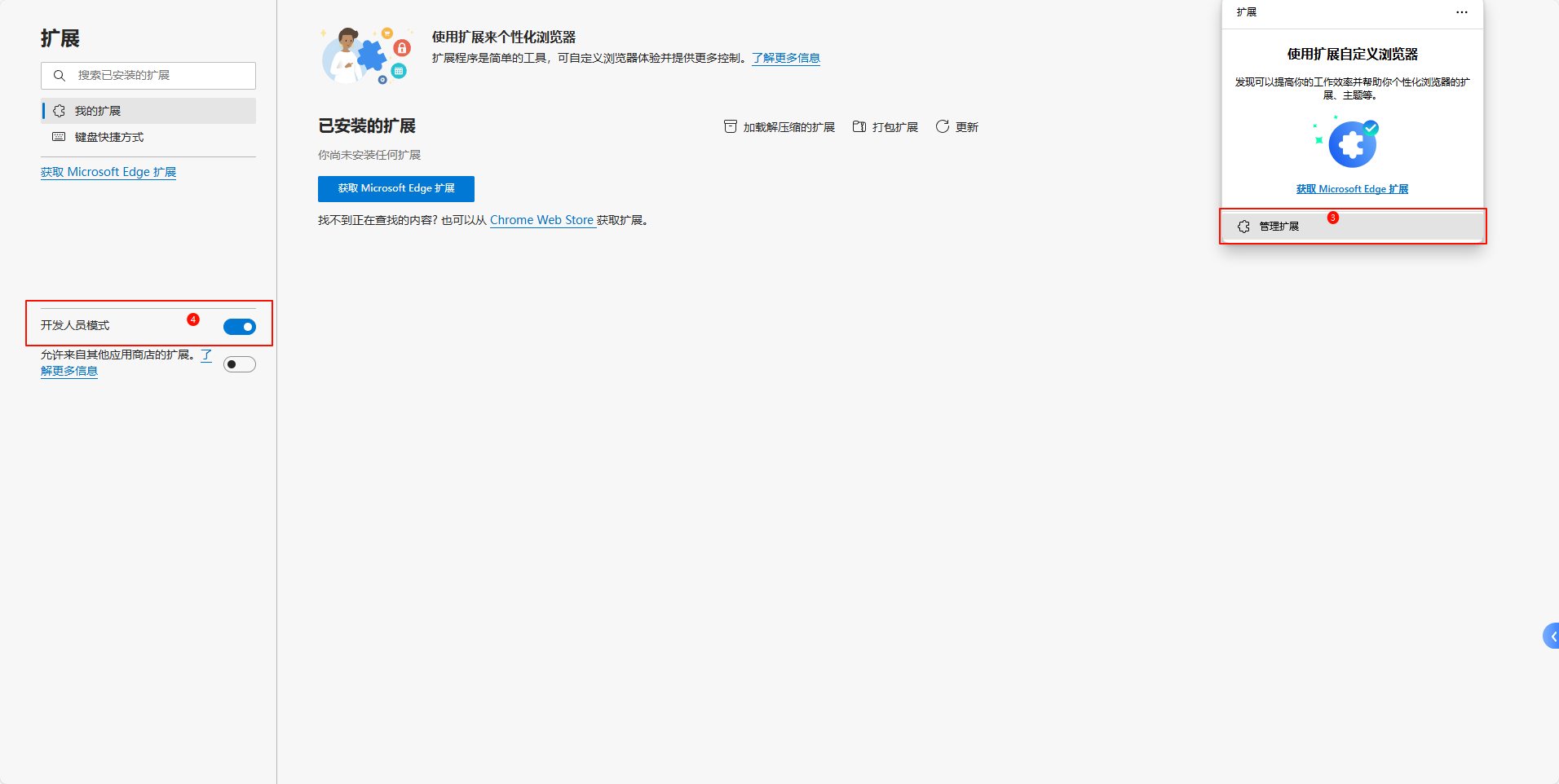
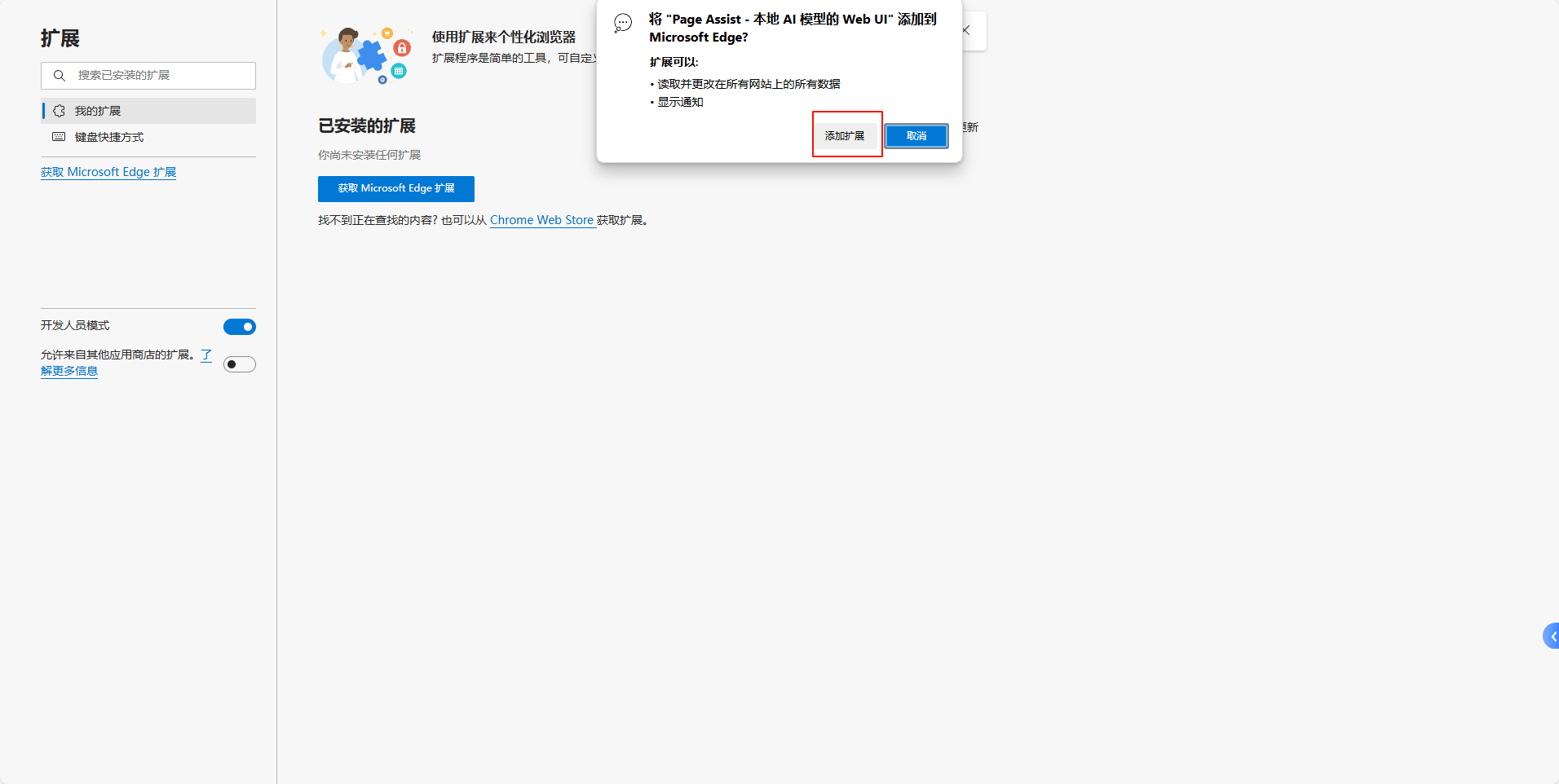
然后把Page Assist安装包拖进来,点击添加扩展
Page Assist连接 LM Studio
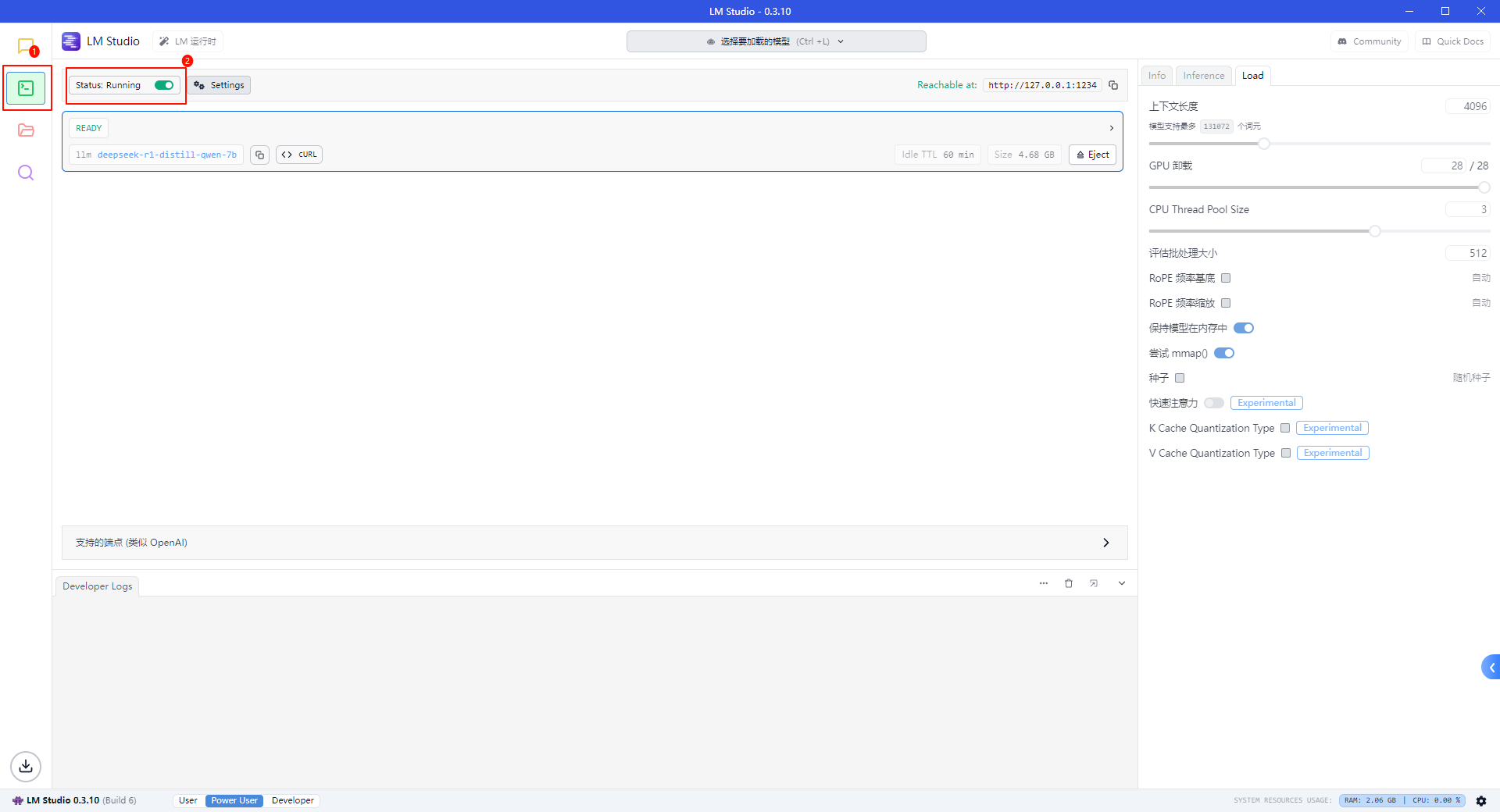
打开 LM Studio 开启本地服务
打开Page Assist扩展
点击设置
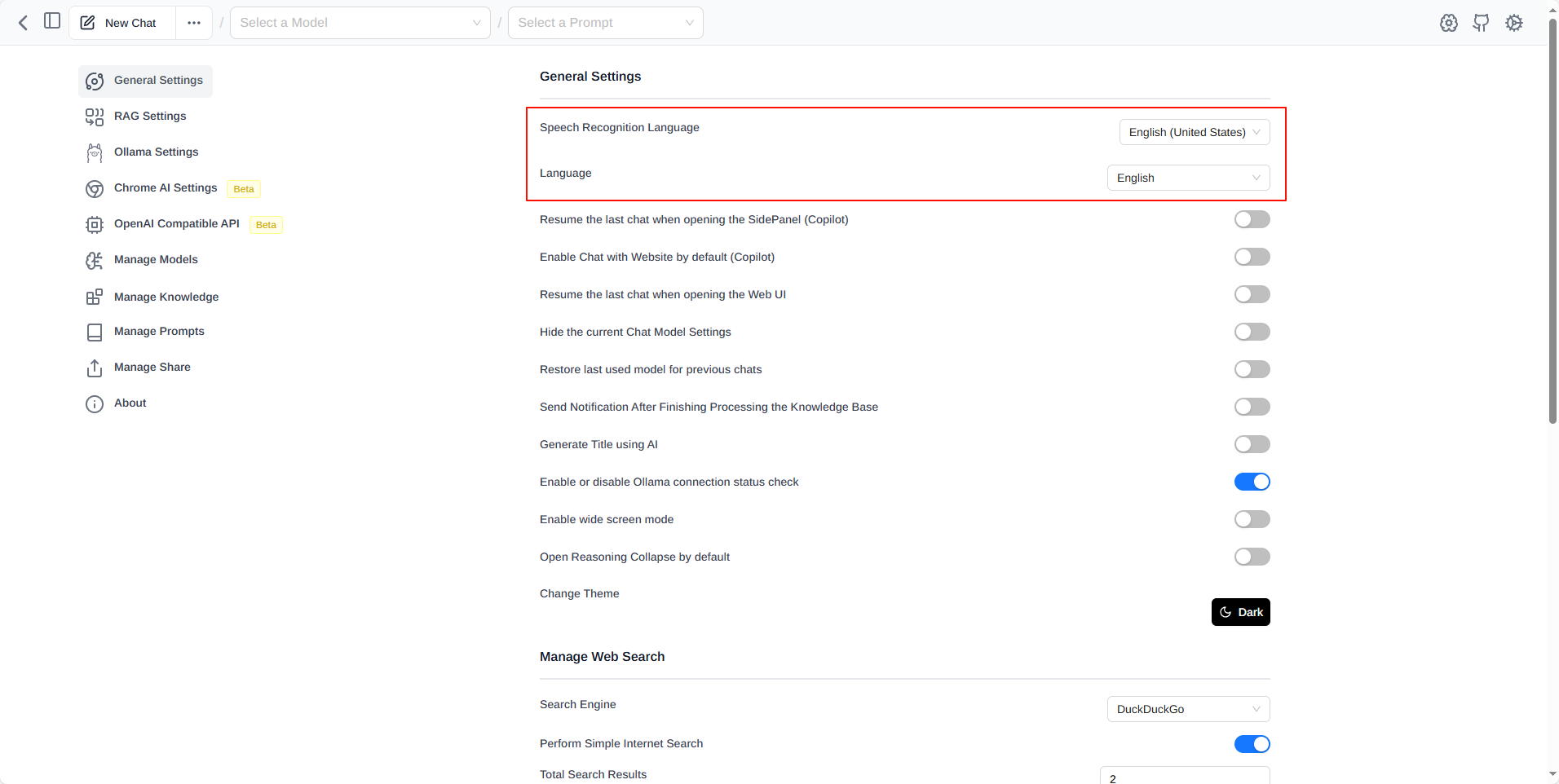
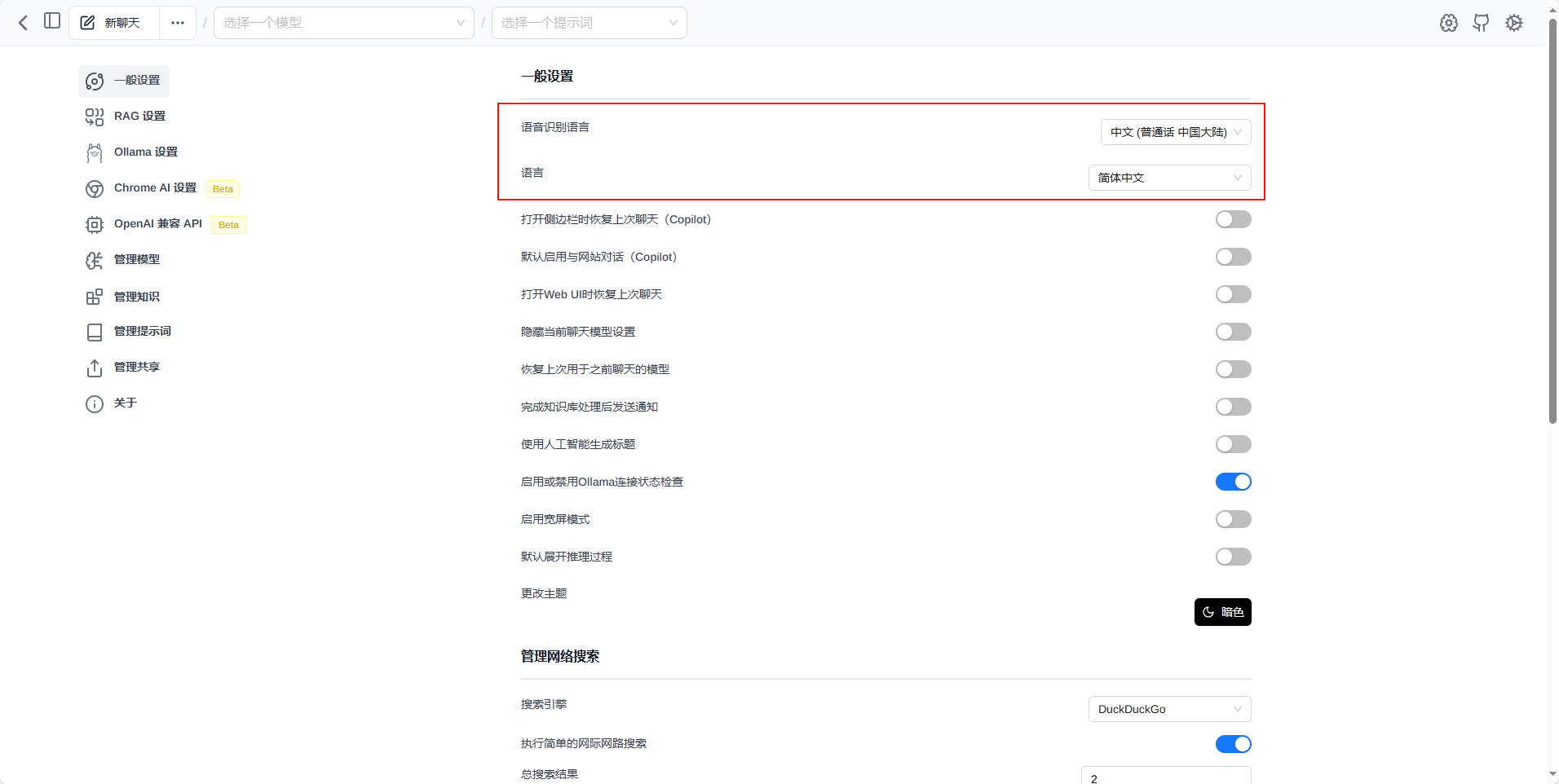
设置中文
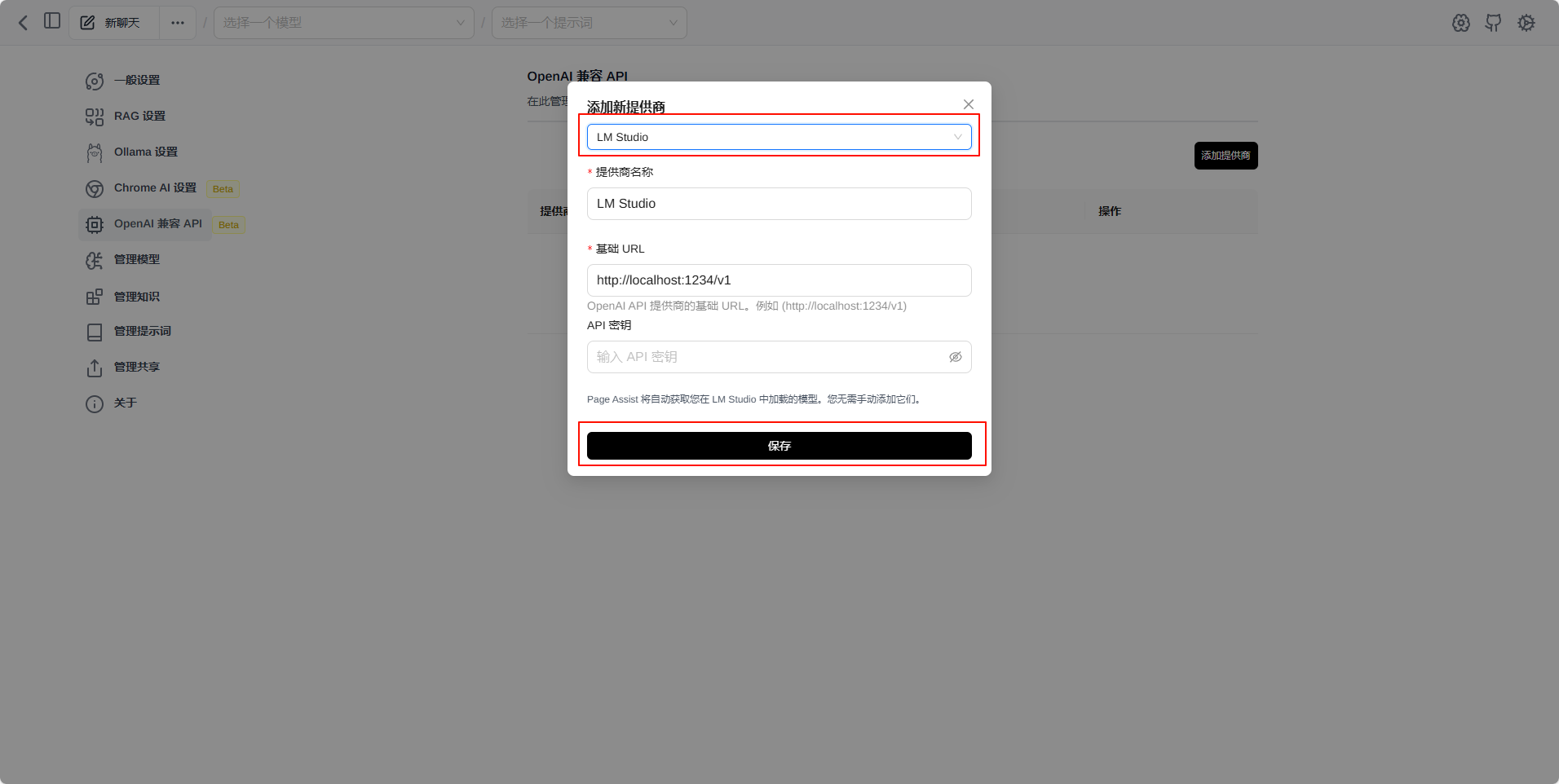
添加模型
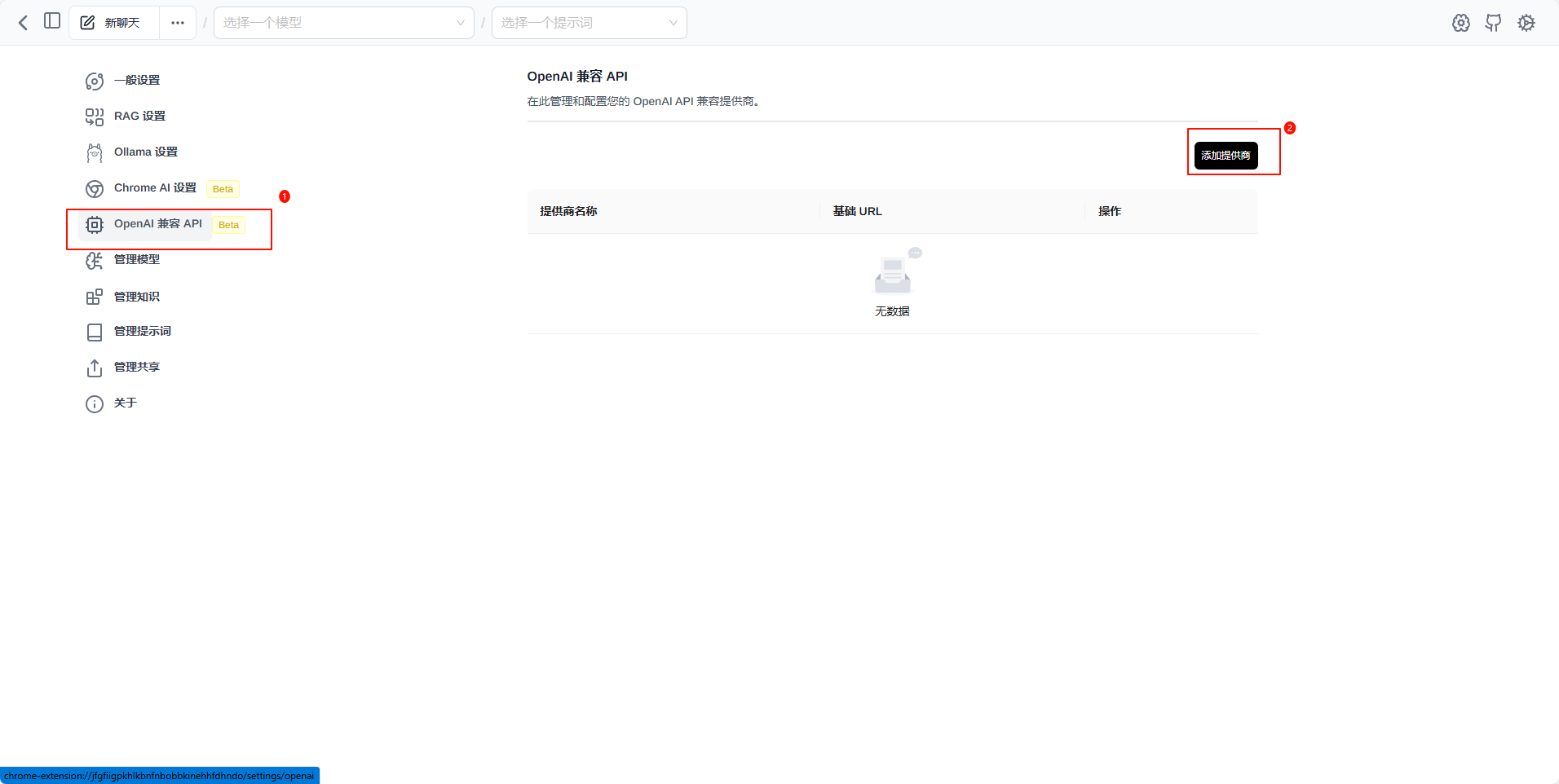
选择LM Studio 然后保存
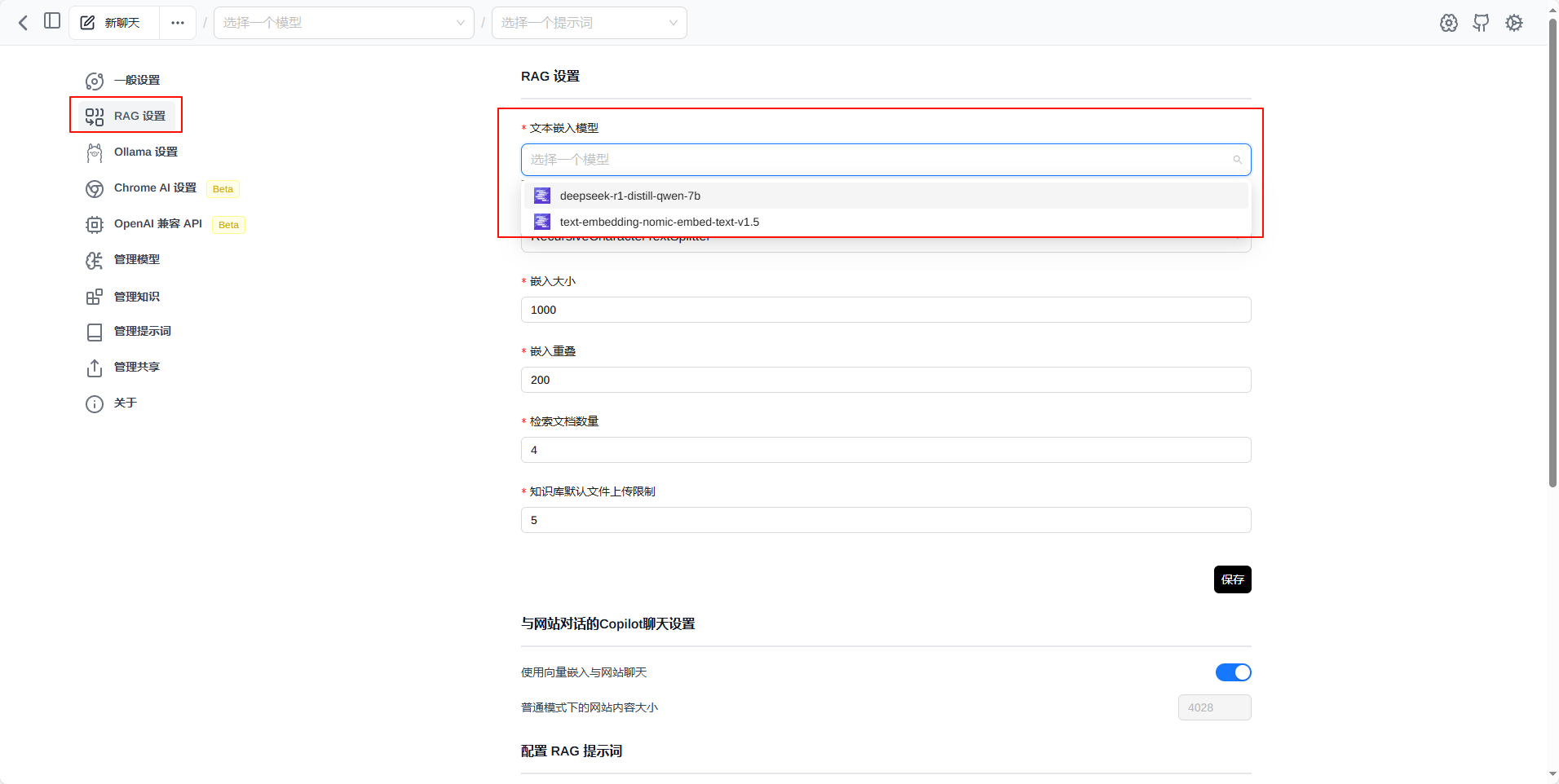
点击 RAG 设置 选择模型并保存
【这一步好像不是必须的】
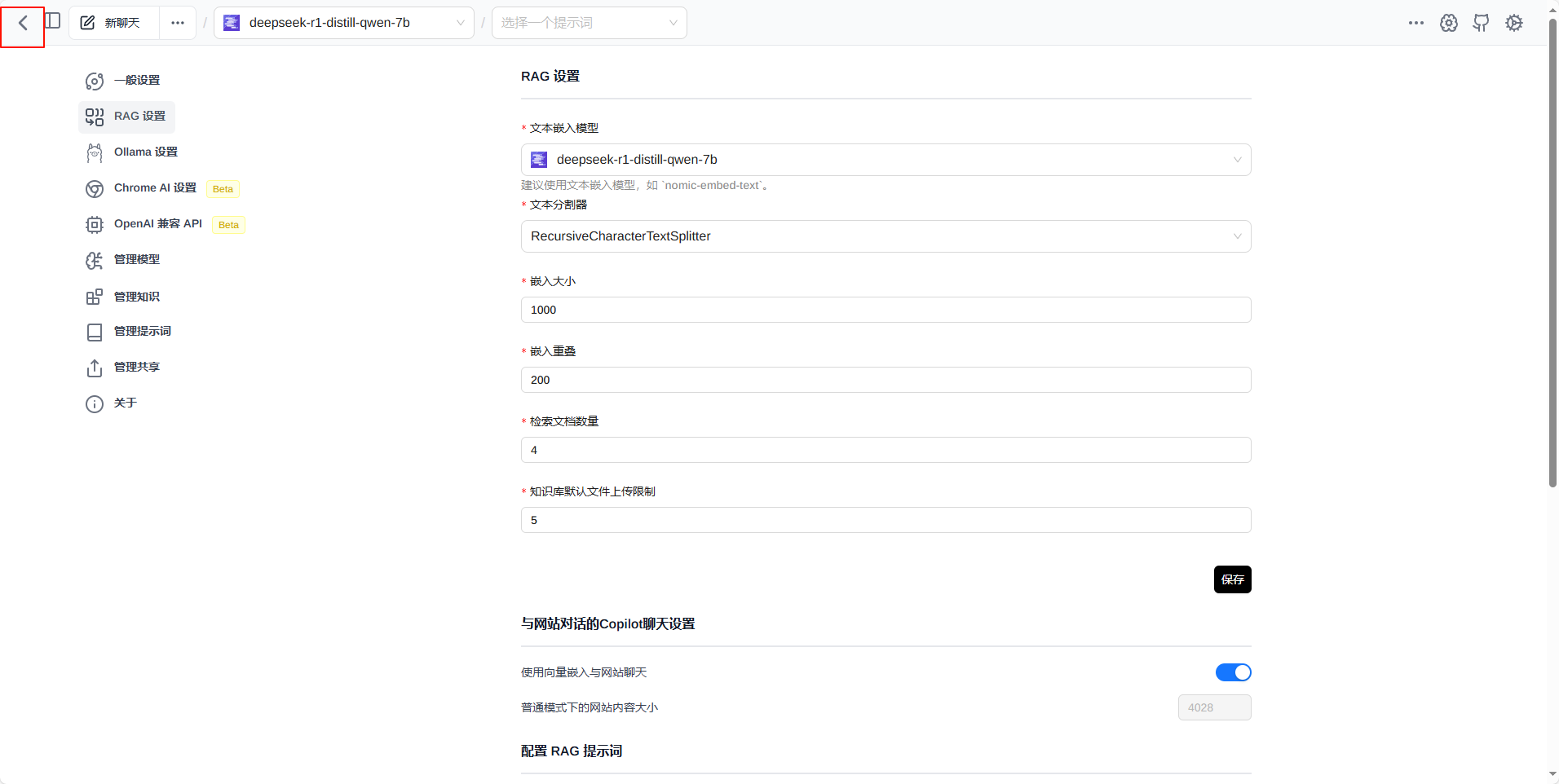
然后返回,选择模型即可使用
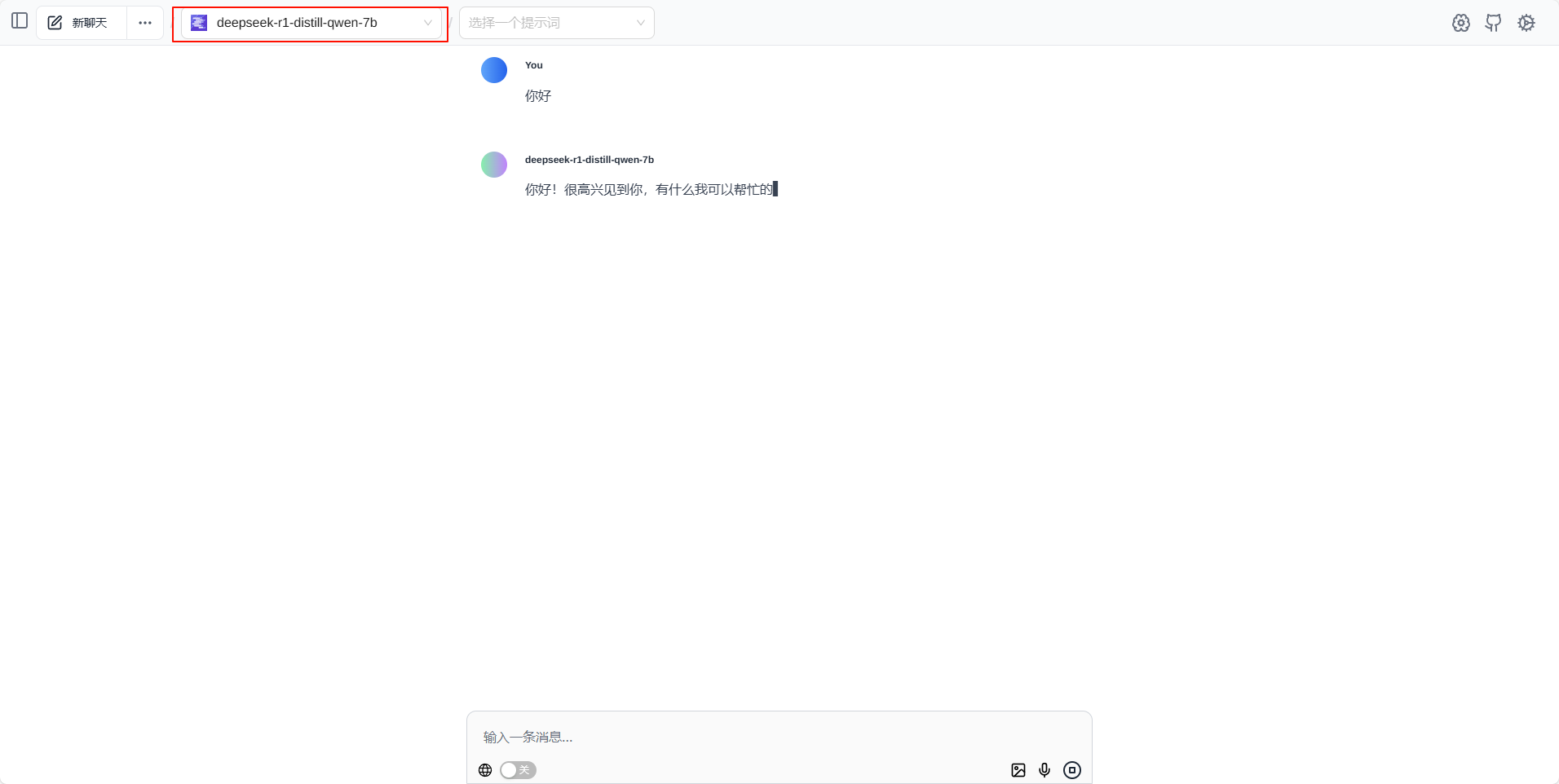
Page Assist连接 Ollama
确定Ollama正在运行
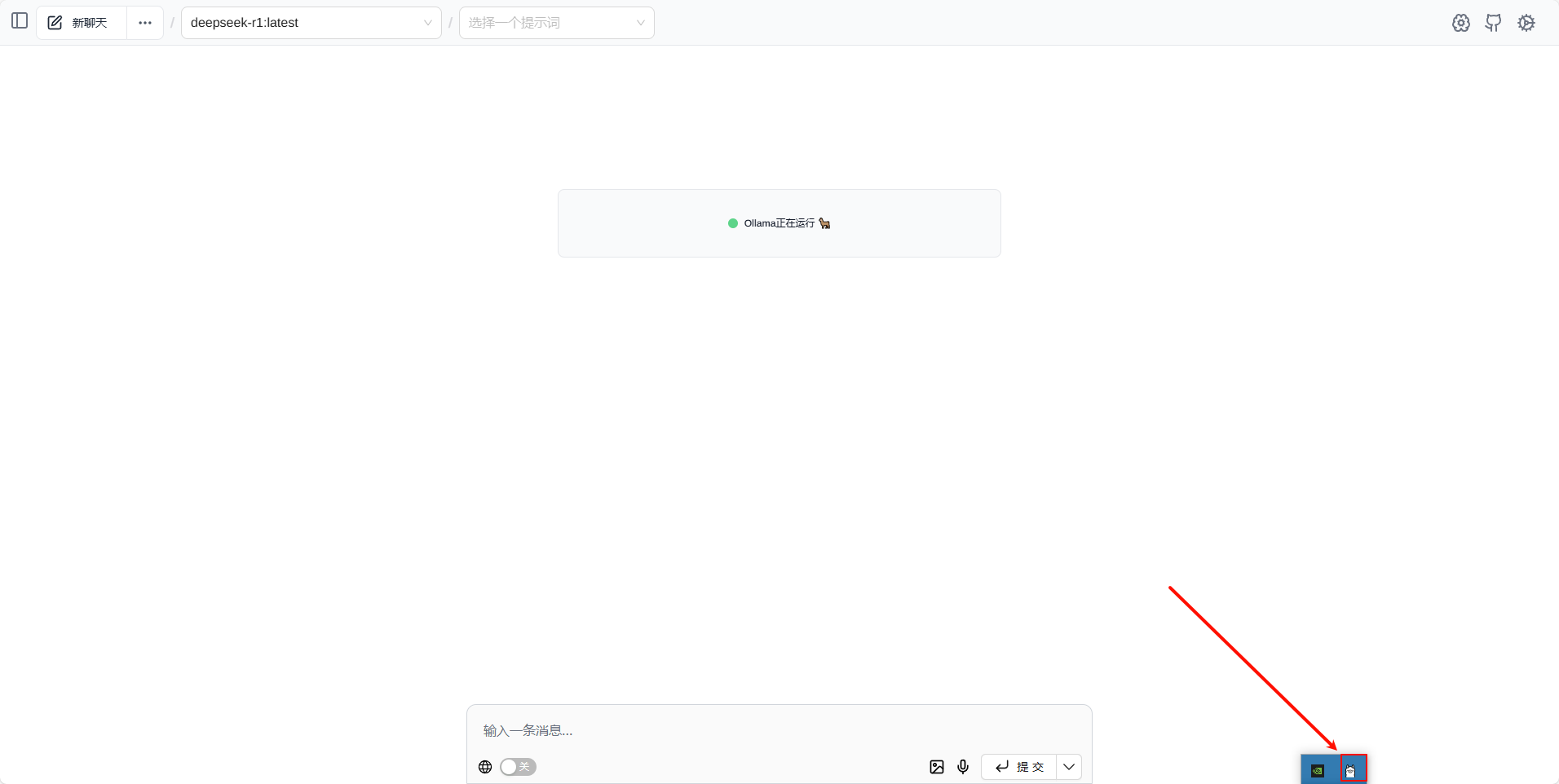
打开Page Assist
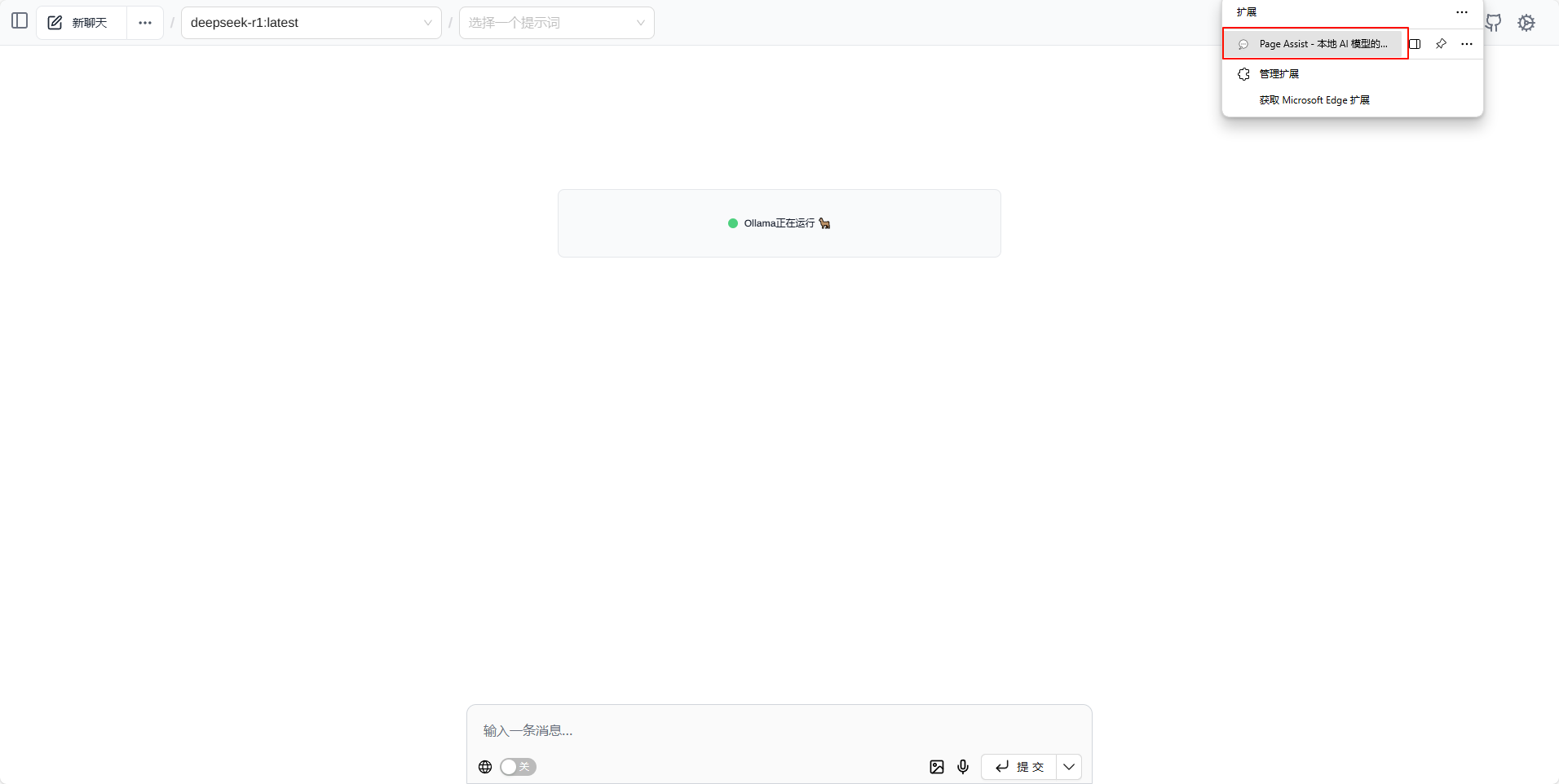
使用
选择对应的模型即可使用