Appearance
Solr8.11.x集群部署
0. 前置
当前部署是以Centos7.9、JDK1.8的环境进行测试的(solr8.11.x需要jdk1.8+)
部署示例为:zookeeper3.8.4、solr 8.11.3
确保您已经有了jdk环境,再进行以下操作
如果您安装较新的jdk可能会出现以下错误:
bash[root@solr ~]# java -version -bash: /data/jdk1.8/bin/java: /lib/ld-linux.so.2: bad ELF interpreter: 没有那个文件或目录解决方式:
bash[root@solr ~]# yum install glibc.i686 -y离线可以通过其他方式下载安装,注意依赖关系:
bash安装:glibc.i686 0:2.17-326.el7_9 作为依赖被安装: nss-softokn-freebl.i686 0:3.90.0-6.el7_9 glibc.x86_64 0:2.17-326.el7_9 glibc-common.x86_64 0:2.17-326.el7_9 nspr.x86_64 0:4.35.0-1.el7_9 nss-softokn-freebl.x86_64 0:3.90.0-6.el7_9 nss-util.x86_64 0:3.90.0-1.el7_9
1. 部署zookeeper
Apache ZooKeeper 下载地址:https://zookeeper.apache.org/releases.html
1.1 上传至服务器解压
多台服务器就分别上传,进行解压,解压后的目录名可以自行修改;
一台服务器就上传一个包,解压后复制即可
tar -xvf apache-zookeeper-3.8.4-bin.tar.gz1.2 配置zk
注意这里需要分两种情况:
情况1:只有一台服务器,伪分布式部署zk(以三个节点为例,解压后的目录复制两份,分别改名为:zk01、zk02、zk03)
bash
## 进入解压后的zk目录下的conf目录
## 复制或改名为zoo_sample.cfg为zoo.cfg
## 修改zoo.cfg内的内容:
## 在zk01、zk02、zk03的目录下新建data目录
## 进入data目录分别通过echo 1 > myid;echo 2 > myid;echo 3 > myid新建zk信息文件
## 此处的dataDir、clientPort是zk01、zk02、zk03三个目录下各自conf下的zoo.cfg文件内的内容
## 数据目录
dataDir=/data/zk01/data
dataDir=/data/zk02/data
dataDir=/data/zk03/data
## 设置端口
clientPort=2181
clientPort=2182
clientPort=2183
## 在末尾添加,所有节点都一样,IP和端口可根据实际情况调整
server.1=127.0.0.1:2187:2887
server.2=127.0.0.1:2188:2888
server.3=127.0.0.1:2189:2889其他zk设置按自己需要来
情况2:有多个服务器,直接上传解压,修改以下配置即可(以三个节点为例)
bash
## 进入解压后的zk目录下的conf目录
## 复制或改名为zoo_sample.cfg为zoo.cfg
## 修改zoo.cfg内的内容:
## 在三台服务器进入zk目录,新建data目录
## 在各节点data目录分别通过echo 1 > myid;echo 2 > myid;echo 3 > myid新建zk信息文件
## 此处的dataDir、clientPort是各服务器zk目录下conf下的zoo.cfg文件内的内容
## 数据目录
dataDir=/data/zk/data
## 设置端口
clientPort=2181
## 在末尾添加,所有节点都一样,IP和端口可根据实际情况调整
server.1=10.1.1.101:2888:3888
server.2=10.1.1.102:2888:3888
server.3=10.1.1.103:2888:3888其他zk设置按自己需要来
1.3 启动zk
通过环境变量/zk的bin目录下的zkServer.sh来启动
伪分布式可参考:
bash
#!/bin/bash
echo "启动ZK01"
/data/zk01/bin/zkServer.sh start
echo "启动ZK02"
/data/zk02/bin/zkServer.sh start
echo "启动ZK03"
/data/zk03/bin/zkServer.sh start分布式参考:
可以给zk配置环境变量:
bash
export ZOOKEEPER_HOME=/data/zk
PATH=$PATH:$ZOOKEEPER_HOME/bin然后在各节点通过环境变量在任意位置使用以下命令启动
bash
zkServer.sh start也可以在zk的bin目录下:
bash
./zkServer.sh start
# 或使用绝对路径,如
/data/zk/bin/zkServer.sh start1.4 测试
单机伪分布可以使用以下命令进行测试
bash
/data/zk01/bin/zkServer.sh status
/data/zk02/bin/zkServer.sh status
/data/zk03/bin/zkServer.sh status如下:
bash
[root@solr ~]# /data/zk01/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zk01/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@solr ~]# /data/zk02/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zk02/bin/../conf/zoo.cfg
Client port found: 2182. Client address: localhost. Client SSL: false.
Mode: leader
[root@solr ~]# /data/zk03/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zk03/bin/../conf/zoo.cfg
Client port found: 2183. Client address: localhost. Client SSL: false.
Mode: follower分布式:
bash
# 各节点使用以下命令,有环境变量
zkServer.sh status
# 没有环境变量,各节点使用以下命令,如
/data/zk/bin/zkServer.sh start
## 或在zk的bin目录下执行
./zkServer.sh status如下:
bash
[root@solr ~]# /data/zk/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zk/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@solr ~]# /data/zk/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zk/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
[root@solr ~]# /data/zk/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zk/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower2. 部署Solr
Apache Solr 下载地址:https://solr.apache.org/downloads.html
2.1 上传至服务器解压
多台服务器就分别上传,进行解压,解压后的目录名可以自行修改;
一台服务器就上传一个包,解压后复制即可
tar -xvf solr-8.11.3.tgz2.2 配置solr
此块的配置仅配置solr.in.sh文件,不需要在server/solr下的solr.xml或者其他文件,其他地方会用solr.in.sh文件内的配置覆盖,如果需要对某个文件做配置也是可以的
注意:如果选择容器化部署,部分参数,如SOLR_OPTS等可能是优先使用环境变量的,需要自行判断
注意这里需要分两种情况:
情况1:只有一台服务器,伪分布式部署solr(以四个节点为例,解压后的目录复制两份,分别改名为:solr01、solr02、solr03、solr04)
编辑各solr目录下的bin目录下的solr.in.sh文件
主要需要关注(尤其是未注释的部分):
bash
# 默认情况下使用JAVA_HOME来确定要使用哪个JAVA,但可以设置Solr使用的绝对路径,而不会影响服务器上的其他JAVA应用程序。
#SOLR_JAVA_HOME=""
# 控制了solr脚本等待solr正常停止的秒数。如果优雅的停止失败,脚本将强制停止Solr。
#SOLR_STOP_WAIT="180"
# 控制solr脚本等待solr启动的秒数。如果启动失败,脚本将放弃等待并显示日志文件的最后几行。
#SOLR_START_WAIT="$SOLR_STOP_WAIT"
# 根据需要增加Java堆以支持 索引/查询 的需求
SOLR_HEAP="1024m"
# 如果需要对内存选项进行更精细的控制,可以直接指定它,注释掉SOLR_HEAP,如果正在使用SOLR_HEAP,那优先使用SOLR_JAVA_MEM
SOLR_JAVA_MEM="-Xms512m -Xmx512m"
# 如果使用外部ZooKeeper集合,请设置ZooKeeper连接字符串
# e.g. host1:2181,host2:2181/chroot
# 如果不使用SolrCloud,则保留为空
## 单机伪分布式使用
ZK_HOST="127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183"
## 分布式使用
# ZK_HOST="10.1.1.101:2181,10.1.1.102:2181,10.1.1.103:2181"
# 如果您的ZK主机有一个chroot路径,并且您想自动创建它,则设置为true。
#ZK_CREATE_CHROOT=true
# 设置ZooKeeper客户端超时(用于SolrCloud模式)
#ZK_CLIENT_TIMEOUT="30000"
# 默认情况下,启动脚本使用 “localhost” 在此处重写生产SolrCloud环境的主机名,以控制暴露在集群状态下的主机名
# 各个节点的IP地址,端口在下面
SOLR_HOST="10.1.1.101"
# 默认情况下,Solr将尝试在30秒的超时时间内连接到Zookeeper;如果需要,覆盖超时
#SOLR_WAIT_FOR_ZK="30"
# 默认情况下,启动脚本使用UTC;如果需要,覆盖时区
#SOLR_TIMEZONE="UTC"
# 设置为“true” 以激活JMX RMI连接器,从而允许远程JMX客户端应用程序监视托管Solr的JVM;
# 设置为“false”以禁用该行为(在生产环境中建议为false)
#ENABLE_REMOTE_JMX_OPTS="false"
# 脚本将使用SOLR_PORT+10000作为RMI_PORT,或者您可以在此处进行设置
# RMI_PORT=18983
# 添加到SOLR_OPTS变量的任何内容都将按原样包含在java启动命令行中,添加到其他选项中。
# 如果在启动脚本时指定-a选项,那么这些选项也将被附加。示例:
#SOLR_OPTS="$SOLR_OPTS -Dsolr.autoSoftCommit.maxTime=3000"
#SOLR_OPTS="$SOLR_OPTS -Dsolr.autoCommit.maxTime=60000"
# bin/solr脚本将保存运行实例的PID文件的位置,如果未设置,脚本将在$solr_TIP/bin中创建PID文件
#SOLR_PID_DIR=
# Solr存储核心及其数据的目录路径。默认情况下,Solr将使用server/Solr
# 如果solr.xml没有存储在ZooKeeper中,则此目录需要包含solr.xml
#SOLR_HOME=
# Solr将用作每个核心的数据文件夹的根目录的路径。
# 如果未设置,则默认为<instance_dir>/data。可通过“dataDir”核心属性按核心重写
#SOLR_DATA_HOME=
# Solr应该将日志写入的位置。绝对或相对于Solr启动目录
#SOLR_LOGS_DIR=logs
# 设置Solr绑定到的端口,默认为8983
## 单机伪分布式的部署方式:IP不变、端口变
## 分布式的部署方式:IP变,端口根据需要是否变
SOLR_PORT=8981
# Linux的安全检查,设置成false
SOLR_ULIMIT_CHECKS=false情况2:有多个服务器,直接上传解压,修改以下配置即可(以四个节点为例)
编辑各solr目录下的bin目录下的solr.in.sh文件
主要需要关注(尤其是未注释的部分):
bash
# 默认情况下使用JAVA_HOME来确定要使用哪个JAVA,但可以设置Solr使用的绝对路径,而不会影响服务器上的其他JAVA应用程序。
#SOLR_JAVA_HOME=""
# 控制了solr脚本等待solr正常停止的秒数。如果优雅的停止失败,脚本将强制停止Solr。
#SOLR_STOP_WAIT="180"
# 控制solr脚本等待solr启动的秒数。如果启动失败,脚本将放弃等待并显示日志文件的最后几行。
#SOLR_START_WAIT="$SOLR_STOP_WAIT"
# 根据需要增加Java堆以支持 索引/查询 的需求
SOLR_HEAP="1024m"
# 如果需要对内存选项进行更精细的控制,可以直接指定它,注释掉SOLR_HEAP,如果正在使用SOLR_HEAP,那优先使用SOLR_JAVA_MEM
SOLR_JAVA_MEM="-Xms512m -Xmx512m"
# 如果使用外部ZooKeeper集合,请设置ZooKeeper连接字符串
# e.g. host1:2181,host2:2181/chroot
# 如果不使用SolrCloud,则保留为空
## 单机伪分布式使用
ZK_HOST="127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183"
## 分布式使用
# ZK_HOST="10.1.1.101:2181,10.1.1.102:2181,10.1.1.103:2181"
# 如果您的ZK主机有一个chroot路径,并且您想自动创建它,则设置为true。
#ZK_CREATE_CHROOT=true
# 设置ZooKeeper客户端超时(用于SolrCloud模式)
#ZK_CLIENT_TIMEOUT="30000"
# 默认情况下,启动脚本使用 “localhost” 在此处重写生产SolrCloud环境的主机名,以控制暴露在集群状态下的主机名
# 各个节点的IP地址,端口在下面
SOLR_HOST="10.1.1.101"
# 默认情况下,Solr将尝试在30秒的超时时间内连接到Zookeeper;如果需要,覆盖超时
#SOLR_WAIT_FOR_ZK="30"
# 默认情况下,启动脚本使用UTC;如果需要,覆盖时区
#SOLR_TIMEZONE="UTC"
# 设置为“true” 以激活JMX RMI连接器,从而允许远程JMX客户端应用程序监视托管Solr的JVM;
# 设置为“false”以禁用该行为(在生产环境中建议为false)
#ENABLE_REMOTE_JMX_OPTS="false"
# 脚本将使用SOLR_PORT+10000作为RMI_PORT,或者您可以在此处进行设置
# RMI_PORT=18983
# 添加到SOLR_OPTS变量的任何内容都将按原样包含在java启动命令行中,添加到其他选项中。
# 如果在启动脚本时指定-a选项,那么这些选项也将被附加。示例:
#SOLR_OPTS="$SOLR_OPTS -Dsolr.autoSoftCommit.maxTime=3000"
#SOLR_OPTS="$SOLR_OPTS -Dsolr.autoCommit.maxTime=60000"
# bin/solr脚本将保存运行实例的PID文件的位置,如果未设置,脚本将在$solr_TIP/bin中创建PID文件
#SOLR_PID_DIR=
# Solr存储核心及其数据的目录路径。默认情况下,Solr将使用server/Solr
# 如果solr.xml没有存储在ZooKeeper中,则此目录需要包含solr.xml
#SOLR_HOME=
# Solr将用作每个核心的数据文件夹的根目录的路径。
# 如果未设置,则默认为<instance_dir>/data。可通过“dataDir”核心属性按核心重写
#SOLR_DATA_HOME=
# Solr应该将日志写入的位置。绝对或相对于Solr启动目录
#SOLR_LOGS_DIR=logs
# 设置Solr绑定到的端口,默认为8983
## 单机伪分布式的部署方式:IP不变、端口变
## 分布式的部署方式:IP变,端口根据需要是否变
SOLR_PORT=8981
# Linux的安全检查,设置成false
SOLR_ULIMIT_CHECKS=false如果需要更详细的配置,或了解更多配置,可以看下面的内容:
bash
# 默认情况下使用JAVA_HOME来确定要使用哪个JAVA,但可以设置Solr使用的绝对路径,而不会影响服务器上的其他JAVA应用程序。
#SOLR_JAVA_HOME=""
# 控制了solr脚本等待solr正常停止的秒数。如果优雅的停止失败,脚本将强制停止Solr。
#SOLR_STOP_WAIT="180"
# 控制solr脚本等待solr启动的秒数。如果启动失败,脚本将放弃等待并显示日志文件的最后几行。
#SOLR_START_WAIT="$SOLR_STOP_WAIT"
# 根据需要增加Java堆以支持 索引/查询 的需求
SOLR_HEAP="1024m"
# 如果需要对内存选项进行更精细的控制,可以直接指定它,注释掉SOLR_HEAP,如果正在使用SOLR_HEAP,那优先使用SOLR_JAVA_MEM
SOLR_JAVA_MEM="-Xms512m -Xmx512m"
# 启用详细GC日志记录。。。
# * 如果未设置,将根据使用的JVM版本选择各种默认选项:
# * 对于Java 8:如果设置了这一点,将添加额外的参数来指定日志文件和转换
# * 对于Java 9或更高版本:每个包含的以“-Xlog:gc”开头但不包括输出说明符的opt-param都
# 将使用SOLR_LOGS_DIR的有效值附加一个“file”输出说明符(以及格式化和滚动选项)。
#
#GC_LOG_OPTS='-Xlog:gc*' # (Java 9+)
#GC_LOG_OPTS="-verbose:gc -XX:+PrintHeapAtGC -XX:+PrintGCDetails \
# -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+PrintTenuringDistribution -XX:+PrintGCApplicationStoppedTime"
# 这些GC设置已被证明适用于许多常见的Solr工作负载
#GC_TUNE=" \
#-XX:+ExplicitGCInvokesConcurrent \
#-XX:SurvivorRatio=4 \
#-XX:TargetSurvivorRatio=90 \
#-XX:MaxTenuringThreshold=8 \
#-XX:+UseConcMarkSweepGC \
#-XX:ConcGCThreads=4 -XX:ParallelGCThreads=4 \
#-XX:+CMSScavengeBeforeRemark \
#-XX:PretenureSizeThreshold=64m \
#-XX:+UseCMSInitiatingOccupancyOnly \
#-XX:CMSInitiatingOccupancyFraction=50 \
#-XX:CMSMaxAbortablePrecleanTime=6000 \
#-XX:+CMSParallelRemarkEnabled \
#-XX:+ParallelRefProcEnabled etc.
# 如果使用外部ZooKeeper集合,请设置ZooKeeper连接字符串
# e.g. host1:2181,host2:2181/chroot
# 如果不使用SolrCloud,则保留为空
ZK_HOST="127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183"
# 如果您的ZK主机有一个chroot路径,并且您想自动创建它,则设置为true。
#ZK_CREATE_CHROOT=true
# 设置ZooKeeper客户端超时(用于SolrCloud模式)
#ZK_CLIENT_TIMEOUT="30000"
# 默认情况下,启动脚本使用 “localhost” 在此处重写生产SolrCloud环境的主机名,以控制暴露在集群状态下的主机名
SOLR_HOST="192.168.100.100"
# 默认情况下,Solr将尝试在30秒的超时时间内连接到Zookeeper;如果需要,覆盖超时
#SOLR_WAIT_FOR_ZK="30"
# 默认情况下,启动脚本使用UTC;如果需要,覆盖时区
#SOLR_TIMEZONE="UTC"
# 设置为“true” 以激活JMX RMI连接器,从而允许远程JMX客户端应用程序监视托管Solr的JVM;
# 设置为“false”以禁用该行为(在生产环境中建议为false)
#ENABLE_REMOTE_JMX_OPTS="false"
# 脚本将使用SOLR_PORT+10000作为RMI_PORT,或者您可以在此处进行设置
# RMI_PORT=18983
# 添加到SOLR_OPTS变量的任何内容都将按原样包含在java启动命令行中,添加到其他选项中。
# 如果在启动脚本时指定-a选项,那么这些选项也将被附加。示例:
#SOLR_OPTS="$SOLR_OPTS -Dsolr.autoSoftCommit.maxTime=3000"
#SOLR_OPTS="$SOLR_OPTS -Dsolr.autoCommit.maxTime=60000"
# bin/solr脚本将保存运行实例的PID文件的位置,如果未设置,脚本将在$solr_TIP/bin中创建PID文件
#SOLR_PID_DIR=
# Solr存储核心及其数据的目录路径。默认情况下,Solr将使用server/Solr
# 如果solr.xml没有存储在ZooKeeper中,则此目录需要包含solr.xml
#SOLR_HOME=
# Solr将用作每个核心的数据文件夹的根目录的路径。
# 如果未设置,则默认为<instance_dir>/data。可通过“dataDir”核心属性按核心重写
#SOLR_DATA_HOME=
# Solr在服务器/资源中提供了一个默认的Log4J配置xml文件。
# 但是,您可能需要自定义日志设置和文件附加器位置,以便可以将脚本指向使用不同的log4j2.xml文件
#LOG4J_PROPS=/var/solr/log4j2.xml
# 更改日志记录级别。有效值:ALL、TRACE、DEBUG、INFO、WARN、ERROR、FATAL、OFF。
# 默认值为INFO这是在log4j2.xml中更改rootLogger的替代方法
#SOLR_LOG_LEVEL=INFO
# Solr应该将日志写入的位置。绝对或相对于Solr启动目录
#SOLR_LOGS_DIR=logs
# 在启动Solr之前启用日志转换。将SOLR_LOG_PRESTART_ROTATION设置为true将使SOLR负责日志的预启动转换。
# 默认情况下这是false,因为log4j2为我们处理此问题。
# 如果您选择使用另一个无法进行启动转换的日志框架,您可能需要启用此功能,以便Solr在启动时转换日志。
#SOLR_LOG_PRESTART_ROTATION=false
# 为所有请求启用码头请求日志
#SOLR_REQUESTLOG_ENABLED=false
# 设置Solr绑定到的端口,默认为8983
SOLR_PORT=8981
# 按IP地址限制对solr的访问
# 指定以逗号分隔的地址或网络列表,例如:
# 127.0.0.1, 192.168.0.0/24, [::1], [2000:123:4:5::]/64
#SOLR_IP_WHITELIST=
# 阻止从特定IP地址访问solr。
# 指定以逗号分隔的地址或网络列表,例如:
# 127.0.0.1, 192.168.0.0/24, [::1], [2000:123:4:5::]/64
#SOLR_IP_BLACKLIST=
# 启用HTTPS。如果您设置了SOLR_SSL_KEY_STORE,那么它实际上是真的。使用此配置可以启用具有自定义码头配置的https模块
#SOLR_SSL_ENABLED=true
# 取消注释以设置SSL相关的系统属性。请确保为您的环境更新到正确密钥库的路径
#SOLR_SSL_KEY_STORE=etc/solr-ssl.keystore.p12
#SOLR_SSL_KEY_STORE_PASSWORD=secret
#SOLR_SSL_TRUST_STORE=etc/solr-ssl.keystore.p12
#SOLR_SSL_TRUST_STORE_PASSWORD=secret
# 要求客户端进行身份验证
#SOLR_SSL_NEED_CLIENT_AUTH=false
# 允许客户端进行身份验证(但不要求)
#SOLR_SSL_WANT_CLIENT_AUTH=false
# 在SSL握手期间验证客户端的主机名
#SOLR_SSL_CLIENT_HOSTNAME_VERIFICATION=false
# SSL证书包含默认情况下验证的主机/IP“对等名称”信息。当在许多主机上重新使用证书时,将其设置为false可用于禁用这些检查
#SOLR_SSL_CHECK_PEER_NAME=true
# 如有必要,覆盖密钥/信任存储类型
#SOLR_SSL_KEY_STORE_TYPE=PKCS12
#SOLR_SSL_TRUST_STORE_TYPE=PKCS12
# 如果要覆盖以前为HTTP客户端定义的SSL值,请取消注释,否则请对其进行注释,并且将自动为HTTP客户端设置上述值
#SOLR_SSL_CLIENT_KEY_STORE=
#SOLR_SSL_CLIENT_KEY_STORE_PASSWORD=
#SOLR_SSL_CLIENT_TRUST_STORE=
#SOLR_SSL_CLIENT_TRUST_STORE_PASSWORD=
#SOLR_SSL_CLIENT_KEY_STORE_TYPE=
#SOLR_SSL_CLIENT_TRUST_STORE_TYPE=
# 设置Hadoop凭据提供程序的路径(Hadoop.security.credential.provider.path属性)并启用凭据存储的使用。
# 凭据提供程序应存储以下密钥:
# * solr.jetty.keystore.password
# * solr.jetty.truststore.password
# 如果要为HTTP客户端设置特定的存储密码,请设置以下两个
# * javax.net.ssl.keyStorePassword
# * javax.net.ssl.trustStorePassword
# 更多信息: https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/CredentialProviderAPI.html
#SOLR_HADOOP_CREDENTIAL_PROVIDER_PATH=localjceks://file/home/solr/hadoop-credential-provider.jceks
#SOLR_OPTS=" -Dsolr.ssl.credential.provider.chain=hadoop"
# 身份验证设置
# 请仅配置SOLR_AUTHENTICATION_CLIENT_BUILDER或SOLR_AUTH_TYPE参数中的一个
#SOLR_AUTHENTICATION_CLIENT_BUILDER="org.apache.solr.client.solrj.impl.PreemptiveBasicAuthClientBuilderFactory"
#SOLR_AUTH_TYPE="basic"
#SOLR_AUTHENTICATION_OPTS="-Dbasicauth=solr:SolrRocks"
# ZK ACL的设置
#SOLR_ZK_CREDS_AND_ACLS="-DzkACLProvider=org.apache.solr.common.cloud.VMParamsAllAndReadonlyDigestZkACLProvider \
# -DzkCredentialsProvider=org.apache.solr.common.cloud.VMParamsSingleSetCredentialsDigestZkCredentialsProvider \
# -DzkDigestUsername=admin-user -DzkDigestPassword=CHANGEME-ADMIN-PASSWORD \
# -DzkDigestReadonlyUsername=readonly-user -DzkDigestReadonlyPassword=CHANGEME-READONLY-PASSWORD"
#SOLR_OPTS="$SOLR_OPTS $SOLR_ZK_CREDS_AND_ACLS"
# Jetty GZIP模块默认启用
#SOLR_GZIP_ENABLED=true
# 使用系统默认值时可能导致操作影响的常见系统值的设置。
# Solr可以使用许多进程和许多文件句柄。在操作系统上,将这些设置保持在较低水平所节省的费用微乎其微,而其后果可能是Solr不稳定。
# 要关闭这些检查,请在此处或作为配置文件的一部分设置SOLR_ULIMIT_checks=false。
# 如果您愿意,也可以在solr.in.sh或您的个人资料中设置不同的限制。
#SOLR_RECOMMENDED_OPEN_FILES=
#SOLR_RECOMMENDED_MAX_PROCESSES=
SOLR_ULIMIT_CHECKS=false
# SOLR_ULIMIT_CHECKS为Linux的安全检查,设置成false
# 避免出现以下错误:
# *** [WARN] *** Your open file limit is currently 1024.
# It should be set to 65000 to avoid operational disruption.
# If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
# *** [WARN] *** Your Max Processes Limit is currently 11215.
# It should be set to 65000 to avoid operational disruption.
# If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
# 在非云模式下运行Solr时,如果计划进行分布式搜索(使用“shards”参数),则需要将主机列表列入白名单,否则Solr将禁止该请求
# 白名单可以在solr.xml中配置,或者如果您使用OOTB solr.xml,可以使用系统属性“solr.shardsWhitelist”指定
# 或者,可以使用系统属性“solr.disable.shardsWhitelist”禁用主机检查
#SOLR_OPTS="$SOLR_OPTS -Dsolr.shardsWhitelist=http://localhost:8983,http://localhost:8984"
# 要在Admin UI中直观地指示此集群的环境类型,请在下面配置-Dsolr.environment属性。
# 有效值为prod、stage、test、dev,带有可选标签或颜色,
# 例如-Dsolr.environment=test,label=Functional+test,color=brown
#SOLR_OPTS="$SOLR_OPTS -Dsolr.environment=prod"
# 指定将在所有核心之间共享的公共库目录的路径。
# 该目录中的任何JAR文件都将添加到Solr插件的搜索路径中。
# 如果指定的路径不是绝对路径,则它将相对于“$SOLR_HOME”。
#SOLR_OPTS="$SOLR_OPTS -Dsolr.sharedLib=/path/to/lib"
# 在java安全管理器沙箱中运行solr。这样可以防止某些攻击。
# 运行时属性被传递到安全策略文件(server/etc/security.policy)
# 您还可以通过标准JDK文件(如~/.java.policy)进行调整,请参阅 https://s.apache.org/java8policy
# 这是实验性的!它可能根本无法与Hadoop/HDFS功能配合使用。
#SOLR_SECURITY_MANAGER_ENABLED=false
# 默认情况下,允许Solr从Solr_HOME和其他一些定义良好的位置读写数据。
# 有时可能需要将核心或备份放置在不同的位置或不同的磁盘上。
# 此参数允许您指定要明确允许的文件系统路径。“*”的特殊值将允许任何路径
#SOLR_OPTS="$SOLR_OPTS -Dsolr.allowPaths=/mnt/bigdisk,/other/path"
# Solr可以尝试对内存不足的错误进行堆转储。要启用此功能,请取消注释行设置SOLR_HEAP_DUMP。
# 默认情况下,堆转储将保存到SOLR_LOG_DIR/dumps。或者,您可以指定任何其他目录,这将隐式启用堆转储。
# 转储名称模式将是 solr-[timestamp]-pid[###].hprof
# 使用此功能时,建议让外部服务监视给定的目录。
# 如果需要更细粒度的控制,可以手动将适当的标志添加到SOLR_OPTS
# 参阅: https://docs.oracle.com/en/java/javase/11/troubleshoot/command-line-options1.html
# 您可以通过设置 SOLR_HEAP=25m 来测试此行为
#SOLR_HEAP_DUMP=true
#SOLR_HEAP_DUMP_DIR=/var/log/dumps
# Solr的一些早期版本使用了过时的log4j依赖项。如果您无法使用log4j 2.15.0版以上的版本
# 然后启用以下设置以寻址CVE-2021-44228
# SOLR_OPTS="$SOLR_OPTS -Dlog4j2.formatMsgNoLookups=true"2.3 上传solr配置到zk
目的是不需要每个节点都配置,只需要在zk上操作即可
在solr根目录下的server/scripts/cloud-scripts/目录下有zkcli.sh脚本,使用此脚本即可完成上传操作,命令参考下面:
bash
./zkcli.sh -zkhost 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183 -cmd upconfig -confname solrconf -confdir /data/solr01/server/solr/configsets/_default/confzkhost:写目标集群的地址
confname:上传后的配置目录名,上传后不是直接的这个名,他会在
/configs下confdir:配置在当前执行脚本服务器的哪个地方
执行结果如下:
bash
[root@solr cloud-scripts]# ./zkcli.sh -zkhost 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183 -cmd upconfig -confname solrconf -confdir /data/solr01/server/solr/configsets/_default/conf
INFO - 2024-03-21 16:32:19.508; org.apache.solr.common.cloud.ConnectionManager; Waiting for client to connect to ZooKeeper
INFO - 2024-03-21 16:32:19.602; org.apache.solr.common.cloud.ConnectionManager; zkClient has connected
INFO - 2024-03-21 16:32:19.603; org.apache.solr.common.cloud.ConnectionManager; Client is connected to ZooKeeper2.4 启动Solr
通过环境变量/solr的bin目录下的solr来启动
伪分布式可参考:
bash
#!/bin/bash
echo "start solr 01"
/data/solr01/bin/solr start -force
echo "start solr 02"
/data/solr02/bin/solr start -force
echo "start solr 03"
/data/solr03/bin/solr start -force
echo "start solr 04"
/data/solr04/bin/solr start -force注意:直接start会有以下报错:
原因是不建议在root用户启动,根据需要添加“-force”或用其他用户启动
WARNING: Starting Solr as the root user is a security risk and not considered best practice. Exiting. Please consult the Reference Guide. To override this check, start with argument '-force'
分布式参考:
可以给solr配置环境变量:
bash
export SOLR_HOME=/data/solr
PATH=$PATH:$SOLR_HOME/bin然后在各节点通过环境变量在任意位置使用以下命令启动
bash
solr start -force也可以在solr的bin目录下:
bash
solr start -force
# 或使用绝对路径,如
/data/solr/bin/solr start -force2.5 开机自启【没试过】
bash
cd /etc/init.d
vi solrbash
#!bin/bash
#chkconfig:2345 55 25
#processname:solr
#description:solr server
prog=/data/solr-8.2.0/bin/solr
start(){
$prog start -force
echo "solr启动"
}
stop(){
$prog stop -all
echo "solr关闭"
}
restart(){
stop
start
}
case "$1" in
"start")
start
;;
"stop")
stop
;;
"restart")
restart
;;
*)
echo "支持指令:$0 start|stop|restart"
;;
esacchkconfig:2345 55 25 # 用于设置开机自启时的运行级别、启动优先级、关闭优先级 processname:solr # 设置启动的进程名 description:solr server # 服务描述
给脚本赋权
bash
chmod +x /etc/init.d/solr执行脚本,进行验证
bash
service solr stop
service solr start这里如果提示找不到jdk,可以在
solr.in.sh内设置SOLR_JAVA_HOME为jdk安装路径的绝对路径
设置开机自启
bash
# 添加开机自启
chkconfig --add solr
# 开启solr启动
chkconfig solr on重启服务器,访问solr管理界面,发现能直接访问,说明开机自启成功
2.6 测试
访问http://其中一个节点的IP:这个节点对应的PORT
出现的页面左侧会有:Cloud
点击Cloud出现资源信息即可
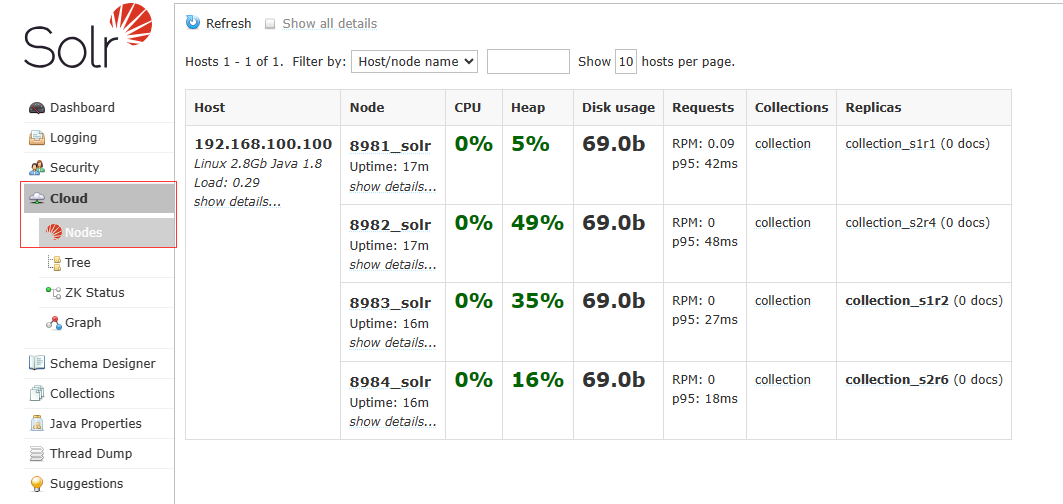
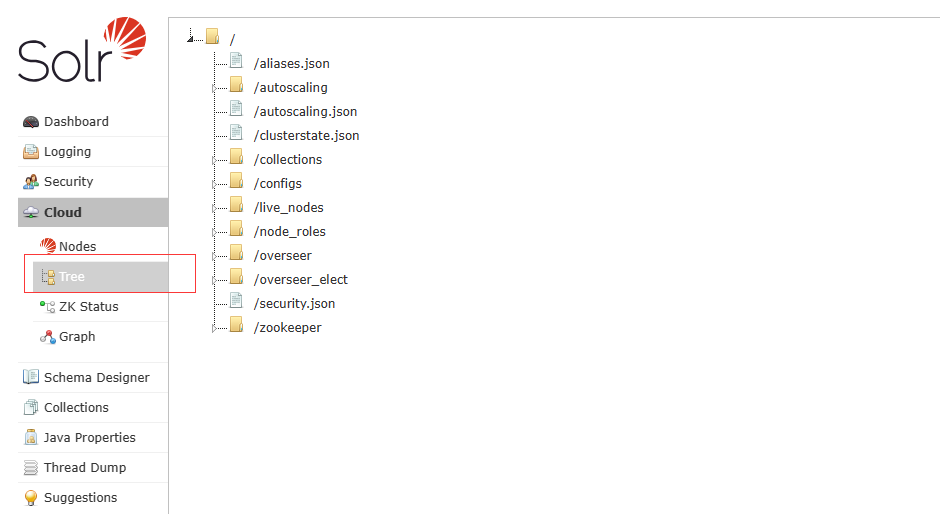
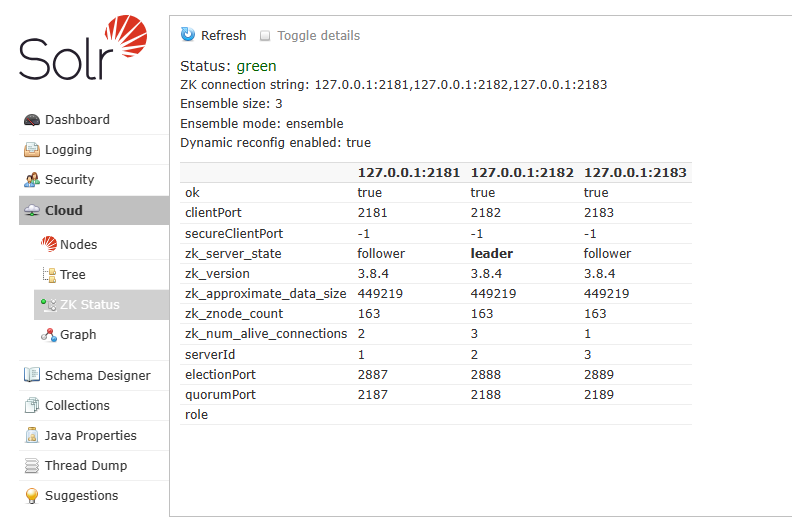
这里能看到zk上的信息
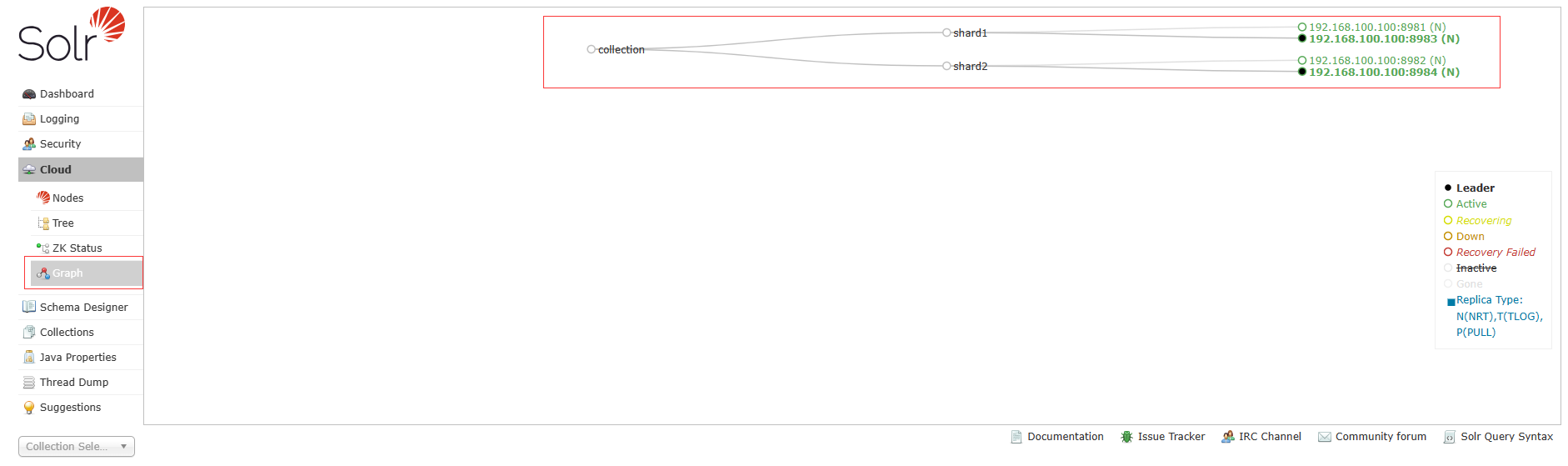
使用如下连接,通过浏览器或其他方式请求,建立分片
http://192.168.100.100:8981/solr/admin/collections?action=CREATE&name=collection&numShards=2&replicationFactor=2&collection.configName=solrconfIP地址和端口写成自己solr某个节点的
name=collection:collection分片名可以自己改
numShards=2:分片数量,根据自己需要写
replicationFactor=2:副本数
collection.configName=solrconf:分片配置名,这里与上传至服务端的配置名一致
创建完成后可以在这里看到图:
如果需要删除参考以下请求连接:
http://192.168.100.100:8981/solr/admin/collections?action=DELETE&name=collection如果在status下有此报错,按提示在zk的配置文件zoo.cfg内,添加4lw.commands.whitelist=mntr,conf,ruok
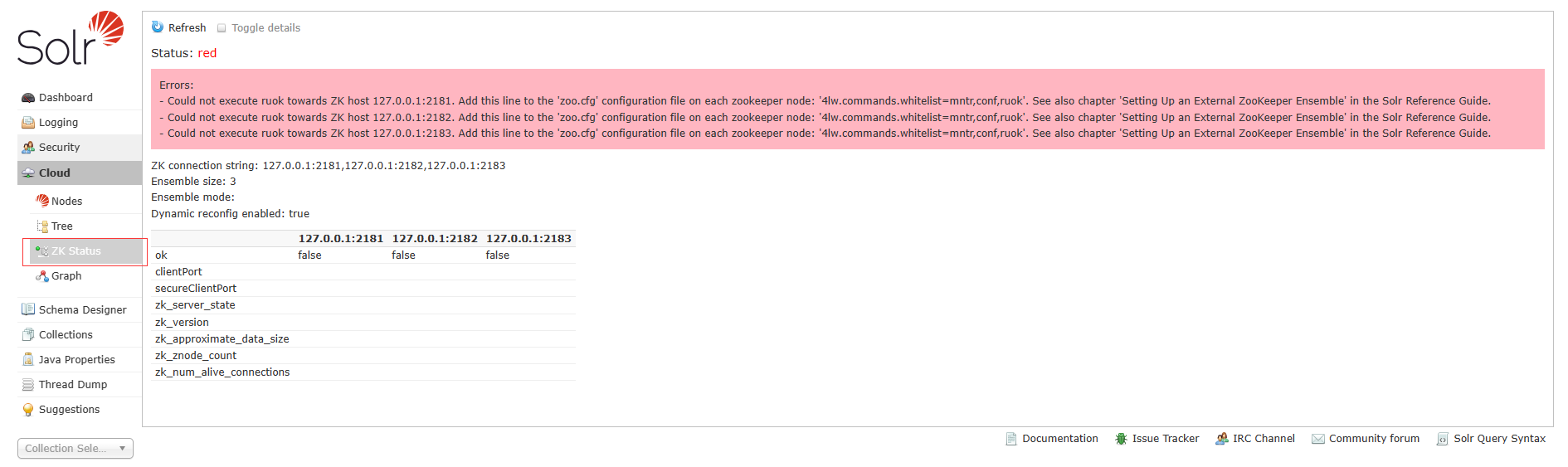
修改完重启zk和solr后:
配置数据同步测试:
以MySQL为例:
需要将solr根目录下dist内的
solr-dataimporthandler-开头的jar包复制或移动到solr根目录下的server/solr-webapp/webapp/WEB-INF/lib/里bashcp dist/solr-dataimporthandler-* server/solr-webapp/webapp/WEB-INF/lib/然后将MySQL的jdbc也导入到
server/solr-webapp/webapp/WEB-INF/lib/目录下
新建:data-config.xml,并写入信息
xml
<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<dataSource name="bzdz_solr" type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://数据库地址:数据库端口/数据库" user="用户" password="密码"/>
<document>
<entity name="V_SOLR_BZDZ" processor="SqlEntityProcessor" pk="id"
query="select id,dzid,dzjb,dzmc,dzjc from xxx where xx=xx"
>
<field column="id" name="id"/>
<field column="dzid" name="dzid"/>
<field column="dzjb" name="dzjb"/>
<field column="dzmc" name="dzmc"/>
<field column="dzjc" name="dzjc"/>
</entity>
</document>
</dataConfig>新建:dataimport.properties,如果文件内为空好像会自己更新
bash
#Fri Mar 22 08:32:41 UTC 2024
V_SOLR_BZDZ.last_index_time=2024-03-22 08\:32\:41
last_index_time=2024-03-22 08\:32\:41修改:managed-schema,搜索<field name或<uniqueKey>id</uniqueKey>在合适的地方添加field字段信息,字段信息与data-config.xml写的一致即可,注意ID是否重复
xml
<!-- 注意已经有了ID,只需要看ID字段是否合适即可,不合适调整,不用再添加ID字段 -->
<uniqueKey>id</uniqueKey>
<field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/>
<field name="dzid" type="string" indexed="true" stored="true"/>
<field name="dzjb" type="string" indexed="false" stored="true"/>
<field name="dzmc" type="string" indexed="true" stored="true"/>
<field name="dzjc" type="string" indexed="true" stored="true"/>注意搜索带以下内容的需要看是否重复或者是否存在
xml
<uniqueKey>id</uniqueKey>
<field name修改:solrconfig.xml在<config></config>内最后添加:
xml
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<!-- data-config.xml 与上面的配置文件名一致即可 -->
<str name="config">data-config.xml</str>
</lst>
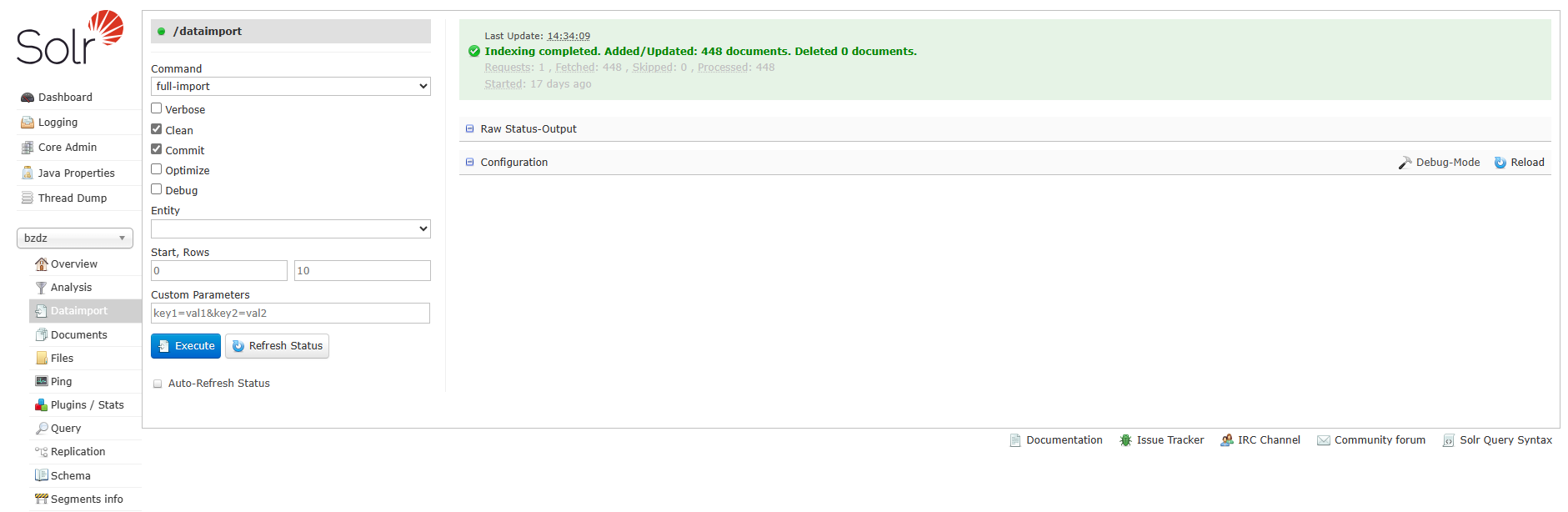
</requestHandler>弄完重启solr,然后查看对应核心是否正常,错误根据错误调整,若正常,点击Dataimport,选择full-import或data-import,点击execute,然后查看是否有导入。若有导入,再query查看是否有内容。
3. solr的核心概念
3.1 核心概念
核心【索引/表】
在es中有索引这个概念,相当于mysql中的表(与mysql中的索引区分开来),而在solr中称之为核心 core, 所以我们可以看到页面上有一个core admin,就是用来管理核心的,也可以将其理解为索引,与es的概念形成关联记忆。和数据库一样,solr的数据就是由一个个core组成。
文档 【doc】
doc全称document, es中也有相同的概念,相当于数据库中的一行数据,一个doc也就表示的一个core中的一条数据
结构 【Schema】
Schema类似于数据库中的表结构,以schema.xml的文本形式存在于conf目录下,在添加数据到索引中时,需要配置Schema。schema中包含:字段、字段类型、唯一键
分词
与传统的数据库模糊查查询不一样,搜索引擎是基于分词查询的,从而来弥补模糊查询不足的地方 举个例子,我们想要查询沙县小吃,那么传统的模糊查询是使用前后模糊匹配,类似 沙县小吃 ,这样的匹配模式,但如果我们的内容只有“沙县”,没有小吃时,就会导致匹配不到我们想要的信息。而分词不同,分词首先就将我们的搜索文本分割成一个个的词组,比如:沙县、小吃,然后分别匹配这些分词在哪个数据中出现的,将其匹配出来,并计算相关度得分。
倒排索引
倒排索引,也叫反向索引,来帮助大家理解solr为什么能实现毫秒级的搜索体验 如下图为普通的正向索引,一句话被对应分割成了一组分词,当我们查询"china"时,会去各个文档的分词组中查询是否存在,这样的做法需要遍历每个文档,数据量较大时,明显就很慢了

而逆向索引的处理刚好相反,以分词为存储的主键,文档ID为值,这样能直接通过分词查询出哪些文档存在该关键字,通过文档ID是顺序存储的,那么也就意味着是有压缩空间的,具体大家可以参考之前书写的关于ES的分词压缩算法,核心思想类似:浅谈倒排索引的两种压缩算法:FOR算法和RBM算法
倒排索引的存储方式,其核心优势就在于当数量特别大时,其在性能的提高和空间上的节约

3.2 solr-admin页面
Dashboard solr的基本信息:可以看到solr的版本、java版本等基础信息
Logging 日志:非常重要的页面,当solr出现问题,比如数据库data-import同步失败时,就可以通过该页面查看日志详情,从而来进行排错
Core Admin 核心/索引管理,类似数据库表管理:可以在Core Admin中进行数据的同步、查询、新增修改、配置文件的查看等
Overview: 概览,一些核心/索引的统计信息 Analysis: 分词查询,如果想知道某个查询词会被分词成什么样,可在这里操作,类似es中的_analyze语句 DataImport: 数据同步,分为增量同步和全量同步 Documents: 数据新增或更新、删除,新增和更新用的都是/update,id存在则更新,不存在则新增 Files: 配置文件信息,也提供了上传或下载文件到solr服务的功能,可以通过此自定义查询组件 Ping: 用于测试与solr服务器之前的连接是否正常 Plugins/Stats:插件管理页面,可以查看、启用、禁用已经安装了的solr插件 Query:查询页面,提供在线查询solr数据的页面 Replication:管理solr分片配置 Schema:管理solr索引结构 Segments info:查看solr索引的段信息,了解索引大小、文档数量、字段等信息
Java Properties java相关属性
Thread Dump 线程相关信息
3.3 managed-schema标签
core核心是solr中的重中之重,类似数据库中的表,在搜索引擎中也叫做索引,在solr中索引的建立,要先创建基础的数据结构,即schema的相关配置
schema标签
schema实际上就是solr核心的数据结构,即字段的定义集
在solr安装目录下,有这样一个文件夹server/solr/configsets/_default/conf,里面附带了要创建索引的默认的基础配置文件。可以通过复制这个文件夹下的配置文件,来帮助我们快速创建索引
这些文件中有两个核心的配置文件需要掌握:
menaged-schema: 字段配置文件 solrconfig.xml :solr核心配置文件
字段结构的定义都是在managed-schema文件中的,当然有时能看到使用的是schema.xml文件,这是因为solr提供了两种定义模式,默认使用managed-schema,如果需要使用schema.xml,则需要在solrconfig.xml中配置如下标签:
xml
<schemaFactory class="ClassicIndexSchemaFactory"/>通过文件夹server/solr/configsets/_default/conf中复制下来的managed-schema已经有各类标签的使用案例了,只不过都是注释的:
xml
<schema name="example" version="1.5">
<field name="id" type="int" indexed="true" stored="true" multiValued="false" required="true"/>
...
<dynamicField name="*_i" type="pint" indexed="true" stored="true"/>
...
<uniqueKey>id</uniqueKey>
<copyField source="sourceFieldName" dest="destinationFieldName"/>
<fieldtype name="textSimple" class="solr.TextField">
<analyzer>
<tokenizer class="org.lionsoul.jcseg.solr.JcsegTokenizerFactory" mode="detect"/>
</analyzer>
</fieldtype>
<fieldType name="string" class="solr.StrField" sortMissingLast="true"/>
...
</schema>3.3.1 field 字段标签
filed标签用于配置字段信息,该标签中包含如下属性:
name: 字段名称,值要求唯一 type: 字段数据类型
支持哪些常用的数据类型
string 字符串 int, long 整数 float, double 浮点数 date 日期时间 bool 布尔类型 text 文本类型 binary 二进制类型
indexed: 当前字段是否创建索引,默认值为true
这里的索引指的是什么?
因为solr使用倒排索引,所以创建索引的含义,就是将字段值包含在倒排索引中,也就是用该值分词创建倒排索引,从而支持基于该字段的搜索和过滤。
创建索引的好处和坏处?
好处是提高了查询小了,坏处当然是增加了存储空间占用,而且当字段值本身很大时,创建索引也会带来一定的性能损耗。因此在指定索引字段时,也要综合考虑。
stored: 当前字段是否存储,默认为true
是否存储,指的是存储到哪里? 配置该字段的值是否存储到solr本身的存储库中,如果存储,那么当查询后的显示就不需要再查询数据源了,对于只需要排序、索引的字段,则可以设置为false来节约空间
比如设置indexed=true, stored=false, 则表示该字段值用于创建索引,但不做存储吗? 是的,该字段值不做存储,但是值会被分词用于创建倒排索引,如此当查询的结果需要再显示该字段时,就需要再次查询数据源来显示,而查询数据源本身是相对较慢的操作
这里的数据源到底指的是什么? solr的数据源可能是数据库、文件、接口等,比如配置了solr数据是从mysql通过dataimport同步过来了,那么数据源就是mysql,查询数据源就表示通过sql再查一遍mysql,所以速度自然就慢
stored=true的好处和坏处? 好处是提高读取性能,直接存储在solr了,无需再从数据源获取,提高查询效率;坏处当然是占用磁盘空间,对于海量的数据时,如果不需要显示,仅仅只是做索引则不用存储,存储也意味着更高的磁盘、网络IO
docValues: 是否启用点列存储当前字段值,默认为false, 当需要字段做排序或者聚合查询时需要设置为true
什么是点列存储? 点列存储(也叫列存储)是倒排索引之外的一种存储结构,我们更加熟悉的是数据库的行存储,但实际上像oracle,sqlserver都已经在支持列存储,列存储是指的是按照列来进行分组存储 比如我们有如下的几行数据
name age sex address school 张三 28 男 广州市xxx路 南京大学 李四 18 男 北京市xxx路 湖南大学 丽丽 19 女 福州市xxx路 江南大学
这几个数据按行存储的话,在磁盘中的存储方式如下所示 同一行的数据是放在一起的
而列存储的话,就是同一列的数据放在一起
这样存储的好处在于当需要对年龄进行分组的时候,就不需要把全部数据查询一遍,而只需要找到对应列的位置,然后将这一连续空间的数据查询出来,进行聚合操作即可 这样的存储方式,极大的方便了针对数值型字段聚合、重复度高的字段分组、需要排序的字段的查询操作,并且联想一下,针对数值列,重复度高的列,我们还可以进行压缩操作,更加节约存储空间


上述图形中,姓名、地址、学校这些字段也按列存储了,是不是造成浪费了? 其实有这个问题,你大概率是陷入了误区,上述是为了展示按列存储的物理结构,实际的操作时,我们是按需定义的,不要忘记这个属性是在field标签下的,也就是说他是针对某一列设置是否按列存储,所以如果不需要的字段,不设置即可
multiValues: 字段值是否可重复,或者说是否为多个值,默认为false。一般用于数组字段
比如如下的数据中,技能字段skills就是一个数组类型,就需要用multiValues=true标识
json{ "name": "张三", "age": 28, "sex": "男", "address": "广州市xxx路", "school": "南京大学", "skills": [ "Java", "Python", "C++", "数据结构与算法" ] }
默认字段
基于以上的属性我们就可以自定义字段了,但同时solr也提供了一些默认的字段,也称为域
xml
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="_version_" type="plong" indexed="false" stored="false"/>
<field name="_root_" type="string" indexed="true" stored="false" docValues="false" />
<field name="_nest_path_" type="_nest_path_" /><fieldType name="_nest_path_" class="solr.NestPathField" />
<field name="_text_" type="text_general" indexed="true" stored="false" multiValued="true"/>如上所示,其中包括:
id : 文档的唯一标识符,可以指定为数据源中的唯一索引字段
_version_ : 版本号,用于并发控制,每次更新文档,版本值都会自动递增
_root_ : 用于嵌套文档结构,表示潜逃文档所属的最外层文档
_nest_path_: 用于嵌套文档结构,表示嵌套文档在文档中的路径,可以根据该路径来查询嵌套文档
_text_ : 文档的主要内容,用于全文检索
假设有如下文档值:
json
{
"id": "001",
"title": "Solr 学习笔记",
"content": "这是一篇关于 Solr 的学习笔记,包含了 Solr 的介绍、安装、配置和使用等内容。"
}则对应的这几个字段的值是:
json
{
"id": "001", // 文档唯一标识符
"_version_": 1, // 并发控制版本号
"_root_": "001", // 嵌套文档根节点(此处与id相同)
"_nest_path_": "", // 嵌套文档路径(顶级文档为空字符串)
"_text_": [ // 全文检索内容
"这是一篇关于 Solr 的学习笔记,包含了 Solr 的介绍、安装、配置和使用等内容。",
"Solr 学习笔记"
]
}比如有点赞信息时,就会引入嵌套文档
json
{
"id": "002",
"title": "Solr 文档结构示例",
"content": "这是一篇 Solr 文档嵌套结构的示例。",
"_root_": "002", // 根节点为自己
"_nest_path_": "", // 初始情况下为空字符串
"_text_": [
"这是一篇 Solr 文档嵌套结构的示例。",
"Solr 文档结构示例"
],
"like": [ // 嵌套文档:点赞
{
"id": "u001",
"user_name": "Tom",
"_root_": "002", // 父文档ID
"_nest_path_": "/like", // 嵌套路径为 /like
"_text_": ["Tom"]
},
{
"id": "u002",
"user_name": "Jack",
"_root_": "002", // 父文档ID
"_nest_path_": "/like", // 嵌套路径为 /like
"_text_": ["Jack"]
}
]
}3.3.2 dynamicField 动态字段标签
动态字段是用来做什么的? 当出现部分字段名都是类似的,且表示相同的含义时,比如:name_1, name_2, name_3 ,如果有成百上千个这样的字段需要定义,还是很麻烦的,可能你觉得不会有这样的场景,但是在搜索引擎的业务场景下,存在大批量字段是比较常见的事情。
这个时候,就希望能有一个类似通配符匹配配置的模式,来批量定义字段,于是就出现了动态字段,比如上述的name_1, name_2, name_3 我们就可以定义为:
xml
<dynamicField name="name_*" type="pint" indexed="true" stored="true"/>动态字段只能有前缀和后缀两种匹配模式,用*来表示
同时需要注意,在solr中,只有在managed-schema文件中配置过的字段,才能在查询时使用,这与数据库的逻辑是一致的,没有定义过的字段,直接使用就会报错"字段未找到"
3.3.3 uniqueKey 唯一主键标签
solr中默认使用id作为唯一主键,更新和新增时就通过唯一主键是否存在来决定
3.3.4 copyField 复制字段标签
复制字段的意思就是将一个或多个字段的值填充到另一个字段中,主要用来:
将多个字段填充到一个字段方便搜索;
如果目标字段中已经有自己的数据,那么会把复制字段的内容作为附加值添加到目标字段的内容中,从而实现更加全面的搜索覆盖
xml<copyField source="name" dest="search_total"/> <copyField source="content" dest="search_total"/> <copyField source="title" dest="search_total"/>对同一个字段定义不同的分词器,用于不同的搜索场景
比如将某字段值,定义英文分词器,中文分词器,西巴牙语分词器,以应对不同语种的搜索场景
xml<copyField source="name" dest="name_english"/> <copyField source="name" dest="name_chinese"/>
3.3.5 fieldType 字段类型标签
filedType标签主要用于定义字段的分词器、过滤器,实现为不同字段定义不同的分词、过滤器
相当于是定义一个字段类型,然后在类型中指定使用的类,然后在field标签中就可以直接使用这个自定义的类型
如下示例,就定义了一个类型my_text,定义了两个分析器,一个用于索引(index),一个用于查询(query),都是用StandardTokenizerFactory作为默认的分词器,StopFilterFactory作为过滤器,分别用于去除标点和停用词。不同的是查询时额外使用了SynonymGraphFilterFactory从synonyms.txt获取同义词
1、solr有哪些分词器和过滤器?比如:中文中还有常用的中文分词器——IK分词器 2、不清楚同义词、过滤器、停用词作用的,因为是搜索引擎的基础概念,可自行搜索
xml
<fieldType name="my_text" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>filedType标签中常用的属性如下:
name: 定义类型名称
class: 定义类型使用的class类,比如text类型的用的就是solr自带的TextField类
positionIncrementGap 属性指定了位置增量间隔,用于多值字段在索引中处理位置信息,默认是0,也就是每个分词之间存储的间隔
默认为0的话,比如这样的文档:
xml
<doc>
<filed name="id">1</field>
<filed name="content">wu quick study</field>
<filed name="content">solr study</field>
</doc>如果针对content字段设置的fieldType指定了默认positionIncrementGap=0,那么content的位置编号就是:
位置编号 文本 1 wu quick study 2 solr study
如果设置的positionIncrementGap=10,则位置编号为,及文本不是连续存储的
位置编号 文本 1 wu quick study 11 solr study
设置positionIncrementGap的好处和坏处? 设置后可以控制多值字段不同值之间的位置增量,这样solr可以更加准确的计算匹配文档和查询相关度,从而计算结果排名,简言之就是查询的结果排名计算更加准确。当然他的坏处就是占用的空间变大,使得索引变大,那么查询性能就受到影响了
其次,fieldType也支持filed中的以下标签:
indexed:是否可以被索引,默认为 true。
stored:是否可以被存储,默认为 true。
multiValued:是否为多值字段,默认为 false。
docValues:是否启用 DocValues,默认为 false。
termVectors:是否启用 TermVectors,默认为 false。
3.4 创建核心/索引/core
新建索引
方法一:使用命令创建核心Core
bash
solr create -c 核心名方法二:通过页面进行添加
1、在solr安装路径的server/solr文件夹下创建一个新文件夹,名称与索引名称一致,用于存放新索引相关配置文件
cd /data/solr
mkdir server/solr/orders注意,有些时候solr数据目录是
/var/solr/data
2、可以通过复制server/solr/configsets/_default/conf来快速创建新的索引,那么先复制该配置文件夹到创建的orders下
cp -R server/solr/configsets/_default/conf/* server/solr/orders3、修改managed-schema配置文件,因为带了很多默认配置,如果都不需要或者觉得删除麻烦的话,可以重新创建一个managed-schema文件,文件配置内容如下:
注意:
_version_字段要开启索引和排序- 所有字段用到的fieldType要在配置文件中显示配置
xml
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="default-config" version="1.6">
<!-- 默认字段,不需要的可以删除 -->
<field name="id" type="long" indexed="true" stored="true" required="true" multiValued="false" />
<!-- 默认情况下,为long类型启用docValues,因此我们不需要对version字段进行索引 -->
<field name="_version_" type="plong" indexed="false" stored="false"/>
<field name="_text_" type="text_general" indexed="true" stored="false" multiValued="true"/>
<!-- 定义字段 -->
<field name="order_no" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="product_name" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="create_time" type="date" indexed="true" stored="true" required="true" multiValued="false" />
<field name="create_user" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="remarks" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="status" type="int" indexed="true" stored="true" required="true" multiValued="false" />
<field name="address" type="text_general" indexed="true" stored="true" required="true" multiValued="false" />
<field name="labels" type="string" indexed="true" stored="false" required="true" multiValued="true" />
<uniqueKey>id</uniqueKey>
<!-- 要声明使用的type -->
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" docValues="true" />
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="date" class="solr.TrieDateField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- 在本例中,我们将只在查询时使用同义词
<filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.FlattenGraphFilterFactory"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
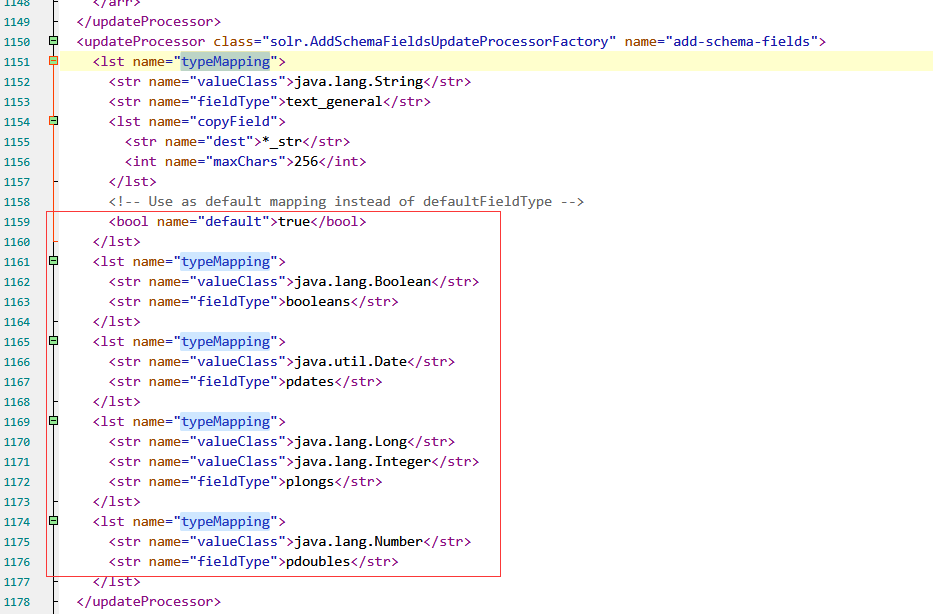
</schema>4、修改solrconfig.xml配置文件,因为里面有一些不需要的默认配置,需要将其去除:
比如这些typeMapper的类型都没用到,自然不需要
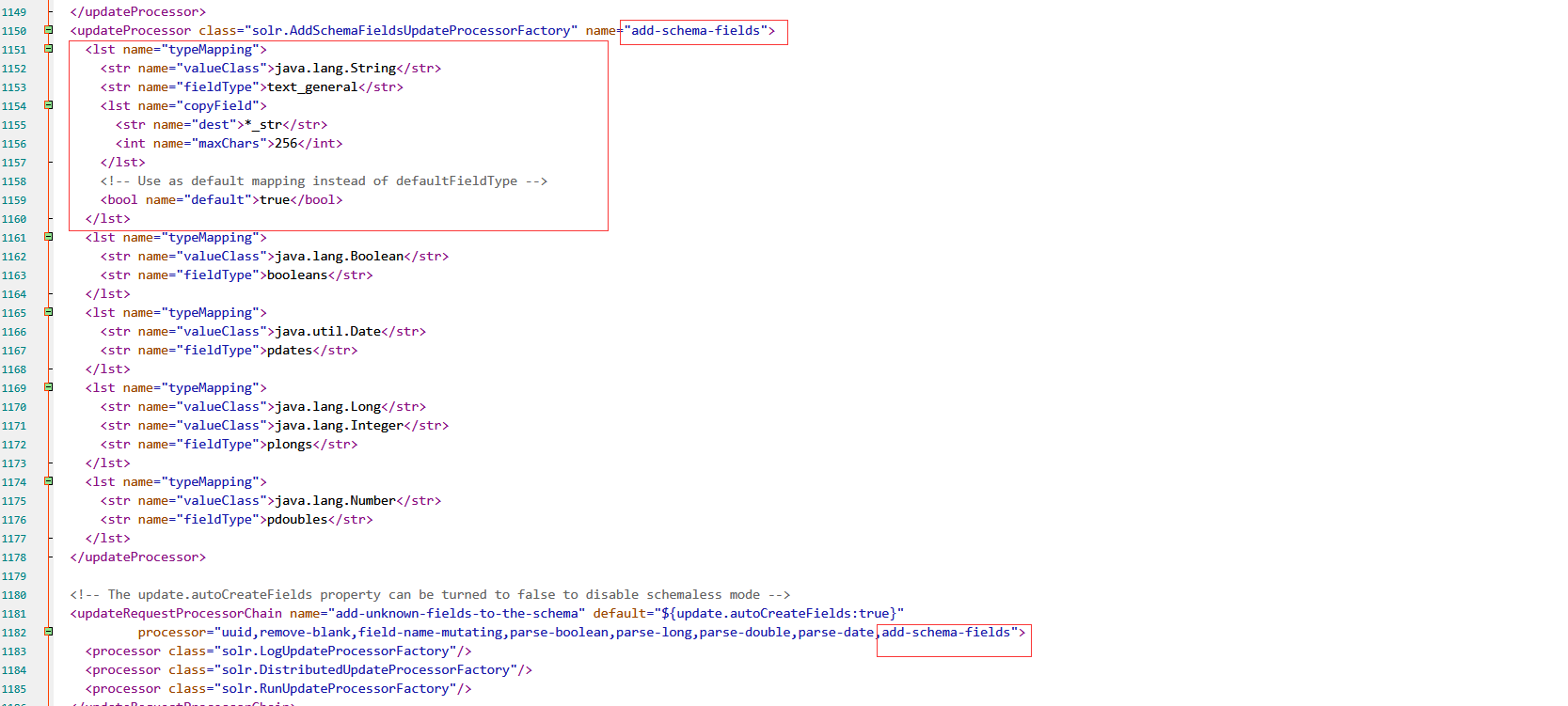
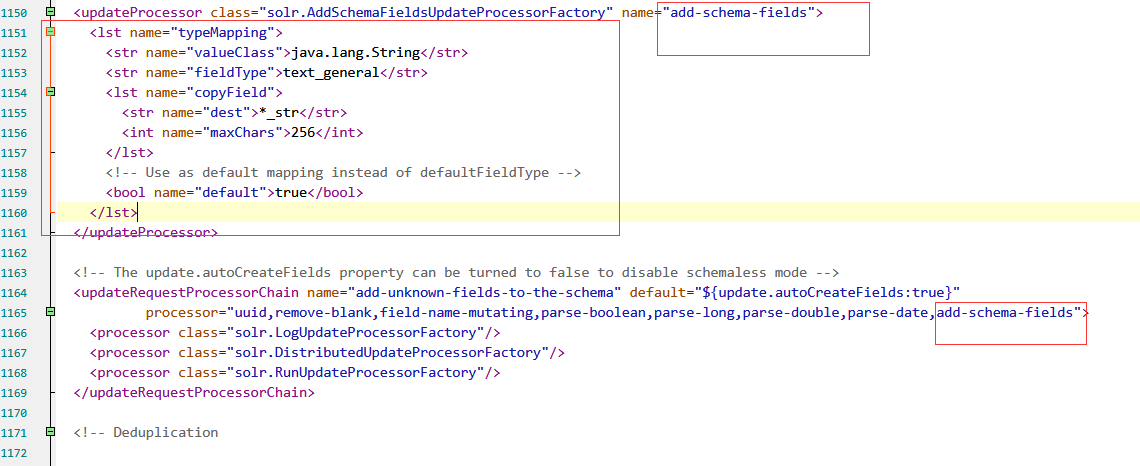
将下图中的add-schema-fields整个updateProcessor标签配置及引用处删除
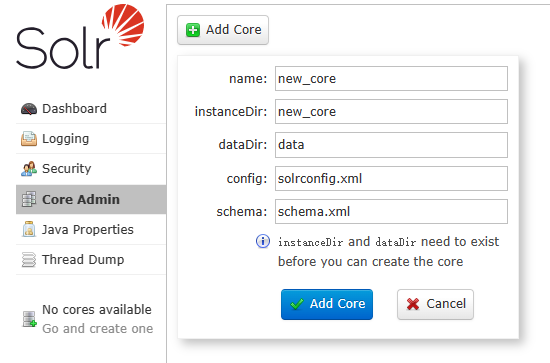
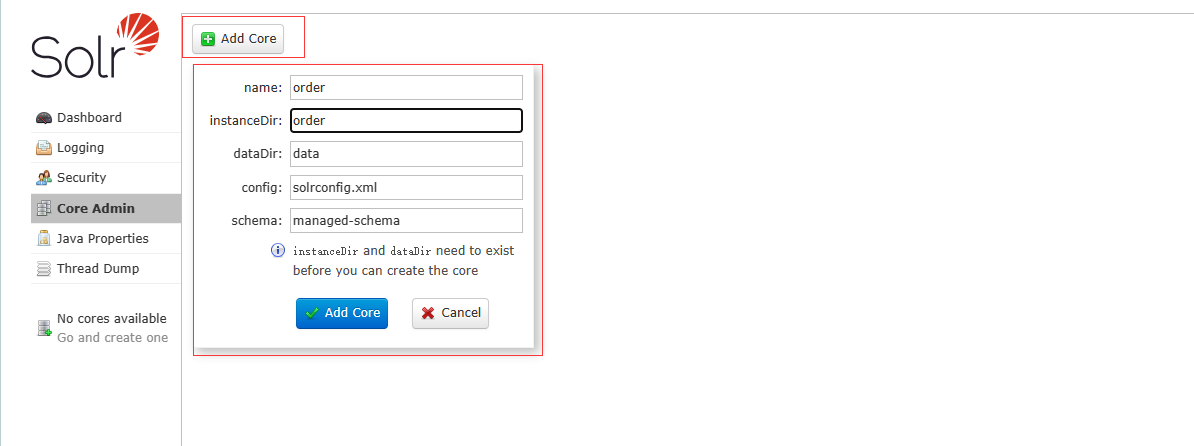
5、在solr管理界面,core-admin菜单,点击add core新增索引,默认采用的是schema.xml的形式,如果想要采用这种形式,需要在server/solr/orders/solrconfig.xml中添加配置<schemaFactory class="ClassicIndexSchemaFactory"/>
这里直接用默认的managed-schema来演示
6、创建成功后,在schema页面可以看到索引的字段结构
3.5 配置从mysql同步数据
数据准备
要配置数据库同步,首先我们要确保我们managed-schema或者schema.xml配置文件中配置的字段和数据库中是能够对应的上的
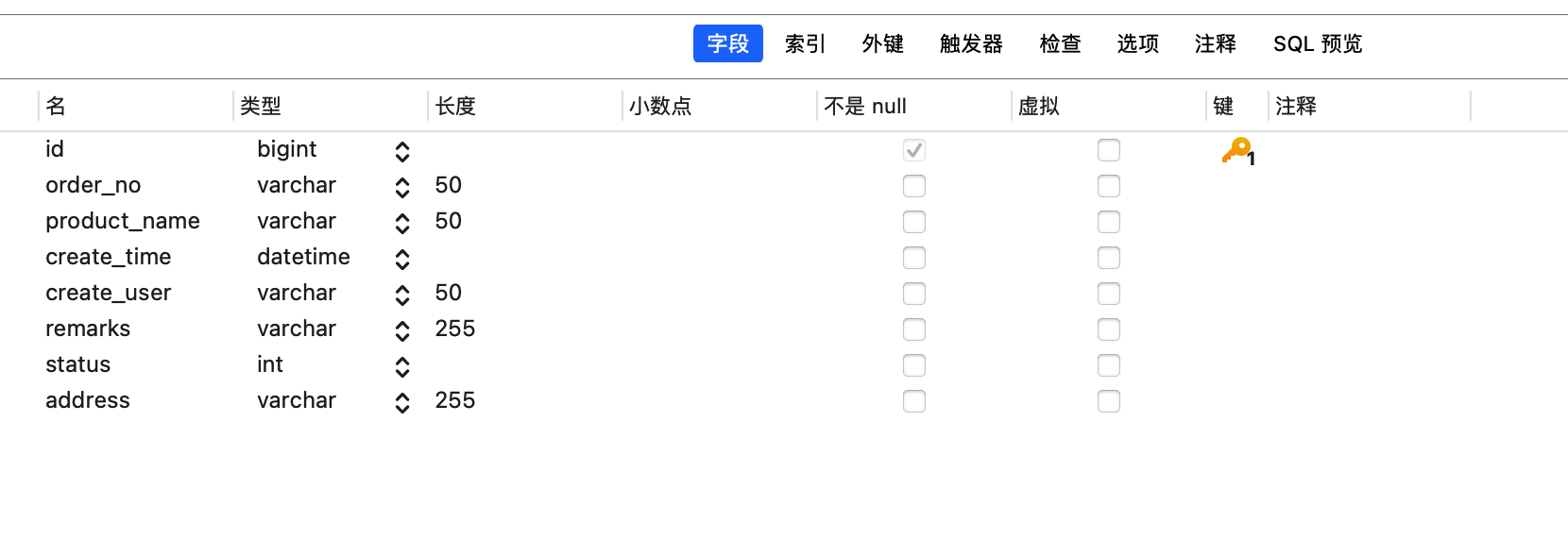
订单表:
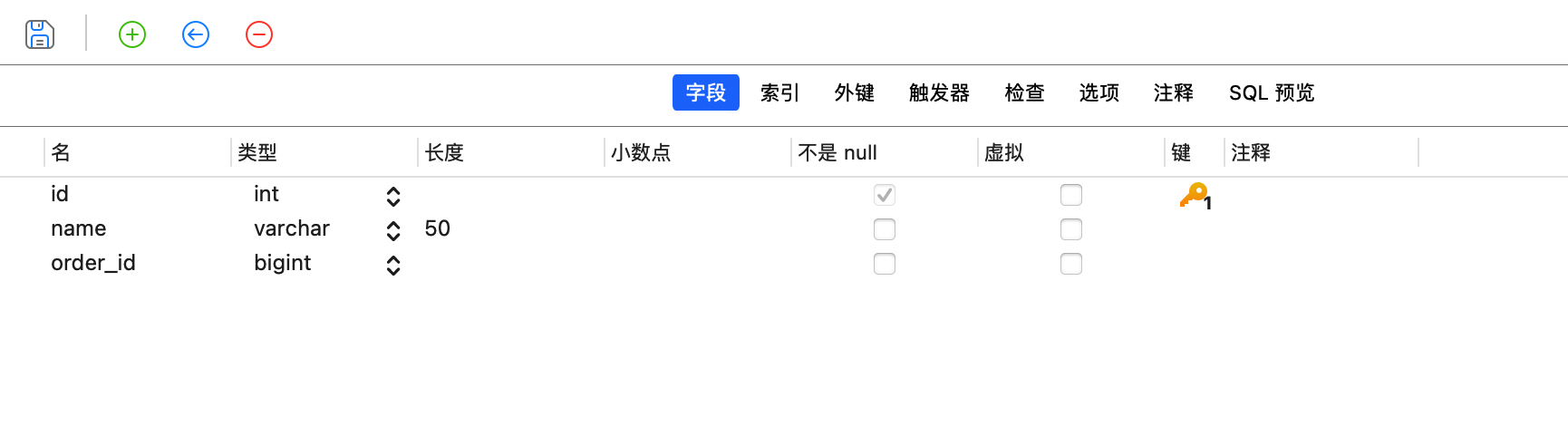
为了模拟关联表同步的效果,我们再创建一张标签子表: 订单标签表
sql
CREATE TABLE `orders` (
`id` bigint NOT NULL,
`order_no` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL,
`product_name` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
`create_user` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL,
`remarks` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
`status` int DEFAULT NULL,
`address` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
CREATE TABLE `orders_label` (
`id` int NOT NULL,
`name` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL,
`order_id` bigint DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;再准备一些数据
sql
# 订单表
INSERT INTO `orders` (`id`, `order_no`, `product_name`, `create_time`, `create_user`, `remarks`, `status`, `address`) VALUES (1, '202306010001', '苹果', '2023-06-01 23:22:26', 'mike', '送货上门,不想下楼', 1, '贵阳市观山湖xxx路');
INSERT INTO `orders` (`id`, `order_no`, `product_name`, `create_time`, `create_user`, `remarks`, `status`, `address`) VALUES (2, '202306010002', '凤梨', '2023-05-09 23:23:12', 'lili', '挑大个的', 1, '贵阳市花溪区ttt路');
INSERT INTO `orders` (`id`, `order_no`, `product_name`, `create_time`, `create_user`, `remarks`, `status`, `address`) VALUES (3, '202306010003', '草莓', '2023-06-01 23:24:20', 'ben', '要红的,注意新鲜', 2, '无锡市滨湖区yyy路');
# 标签表
INSERT INTO `orders_label` (`id`, `name`, `order_id`) VALUES (1, '送货上门', 1);
INSERT INTO `orders_label` (`id`, `name`, `order_id`) VALUES (2, '生鲜', 1);
INSERT INTO `orders_label` (`id`, `name`, `order_id`) VALUES (3, '24小时', 1);
INSERT INTO `orders_label` (`id`, `name`, `order_id`) VALUES (4, '生鲜', 2);
INSERT INTO `orders_label` (`id`, `name`, `order_id`) VALUES (5, '保质服务', 2);
INSERT INTO `orders_label` (`id`, `name`, `order_id`) VALUES (6, '生鲜', 3);
INSERT INTO `orders_label` (`id`, `name`, `order_id`) VALUES (7, '24小时', 3);数据同步配置文件详解
我们实现数据同步的核心在于配置同步配置文件,该配置文件的核心标签和属性如下
dataSource 标签
用于声明同步的数据库地址、账号、密码、驱动器等连接信息 其中batchSize表示每次读取数据库的数量,-1表示不限制,如果同步的数据量较大,可以设置每次读取的限制,防止solr一次性建立索引数据过多导致的内存溢出问题 dataSource标签可以配置多个,用于声明多个数据源,比如需要跨库链接查询时使用,可以通过name标签声明数据库名称
xml<dataSource driver="com.mysql.cj.jdbc.Driver" url="jdbc:mysql://192.168.244.50:3306/test?useUnicode=true&characterEncoding=UTF8&autoReconnect=true&zeroDateTimeBehavior=convertToNull" name="test" user="root" password="123456" batchSize="-1"/>document 标签
document标签用于声明主要文档配置,核心子标签是entity
entity 标签
entity标签就是用来声明我们要同步的sql以及字段映射的,核心的属性如下
name 定义对应的solr中索引/核心名称
pk 主键字段名称,确保实体每一条记录唯一
dataSource 数据源,如果只有一个数据源时可以不用配置,与dataSource标签中的name属性对应
query 定义全量同步时的查询sql
deltaImportQuery 定义增量同步时的查询sql,自带的${dataimporter.delta.id}属性表示正在同步的数据的主键
deltaQuery 定义需要增量同步的id, dataimporter.delta.id 的值也就来源于此, {dataimporter.delta.id}的值也就来源于此,dataimporter.delta.id的值也就来源于此,{dataimporter.last_index_time}表示上一次完成增量同步的时间,由系统自动记录生成
xml
<entity name="orders"
query="select id,order_no,product_name,create_time,create_user,remarks,status,address from orders"
deltaImportQuery="select id,order_no,product_name,create_time,create_user,remarks,status,address from orders WHERE id='${dataimporter.delta.id}'"
deltaQuery="SELECT id FROM orders WHERE create_time >= '${dataimporter.last_index_time}'">
<field name="id" column="id"/>
<field name="order_no" column="order_no"/>
<field name="product_name" column="product_name"/>
<field name="create_time" column="create_time"/>
</entity>实际操作
1、修改solrconfig.xml配置文件,配置数据库同步配置文件
bash
# 进入solr安装目录
cd /data/solr
# orders是创建的索引/核心 文件夹
vi server/solr/orders/solrconfig.xml添加如下内容
xml
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-dataimporthandler-.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="mysql-connector-java-.*\.jar" />
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>2、在server/solr/orders下创建data-config.xml配置文件
这里需要注意,如果要配置父子表同步时再定义一个<entity>标签即可,其中的<field>中的name要与maneged-schema文件中定义的labels保持一致,具体如下
xml
<entity name="lables" pk="id"
query="select name from orders_label where order_id = '${orders.id}'">
<field name="labels" column="name"/>
</entity>完整配置文件:
xml
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource driver="com.mysql.cj.jdbc.Driver"
url="jdbc:mysql://192.168.244.50:3306/test?useUnicode=true&characterEncoding=UTF8&autoReconnect=true&zeroDateTimeBehavior=convertToNull&serverTimezone=UTC&tinyInt1isBit=false"
user="root" password="123456" batchSize="-1"/>
<document>
<entity name="orders"
query="select id,order_no,product_name,create_time,create_user,remarks,status,address from orders"
deltaImportQuery="select id,order_no,product_name,create_time,create_user,remarks,status,address from orders WHERE id='${dataimporter.delta.id}'"
deltaQuery="SELECT id FROM orders WHERE create_time >= '${dataimporter.last_index_time}'">
<field name="id" column="id"/>
<field name="order_no" column="order_no"/>
<field name="product_name" column="product_name"/>
<field name="create_time" column="create_time"/>
<field name="create_user" column="create_user"/>
<field name="remarks" column="remarks"/>
<field name="status" column="status"/>
<field name="address" column="address"/>
<entity name="lables" pk="id"
query="select name from orders_label where order_id = '${orders.id}'">
<field name="labels" column="name"/>
</entity>
</entity>
</document>
</dataConfig>3、在server/solr/orders/conf/下创建dataimport.properties配置文件
bash
mkdir -p /data/solr/server/solr/orders/conf/
vi /data/solr/server/solr/orders/conf/dataimport.properties配置内容为最后同步的时间,如果不填将会自动生成
bash
orders.last_index_time=2023-06-04 02\:25\:054、添加jar包,因为这里用数据库是mysql8.0,所以需要引入com.mysql.cj.jdbc.Driver的驱动器jar包,同时还要引入同步用的jar包solr-dataimporthandler*
(1)将solr安装路径/dist目录下的两个solr-dataimporthandler* jar包复制到server/solr-webapp/WEB-INF/lib下
bash
cd /data/solr
cp dist/solr-dataimporthandler-* server/solr-webapp/webapp/WEB-INF/lib/(2)将数据库驱动jar包(自己下载)也添加到server/solr-webapp/webapp/WEB-INF/lib下
5、重启 solr
6、在solr-admin管理页面,Dataimport菜单中执行同步操作,选择full-import,第一次同步进行一次全量同步
7、如果发现没有同步成功,可以在Logging页面查看日志,点击具体的日志即可查看详情;也可在服务端日志server/logs/solr.log中查询详细报错堆栈信息
8、同步成功后,在输出页面会有绿色的标识,并告知同步了多少条数据
9、在Query菜单,查询全部数据,发现同步成功!
10、数据库新增一条数据
11、在solr-admin中点击delta-import进行增量同步,结果显示同步了一条新增数据,查询可以看到新增的数据
常见报错
1、Error creating document : SolrInputDocument
查看日志是否存在类似于:solrException: [doc=x] missing required field: labels的报错
这个原因是:有一个必填字段labels,但是没有传值进来,导致新增数据失败
修改managed-schema或者schema.xml文件,将该字段设置为非必填即可
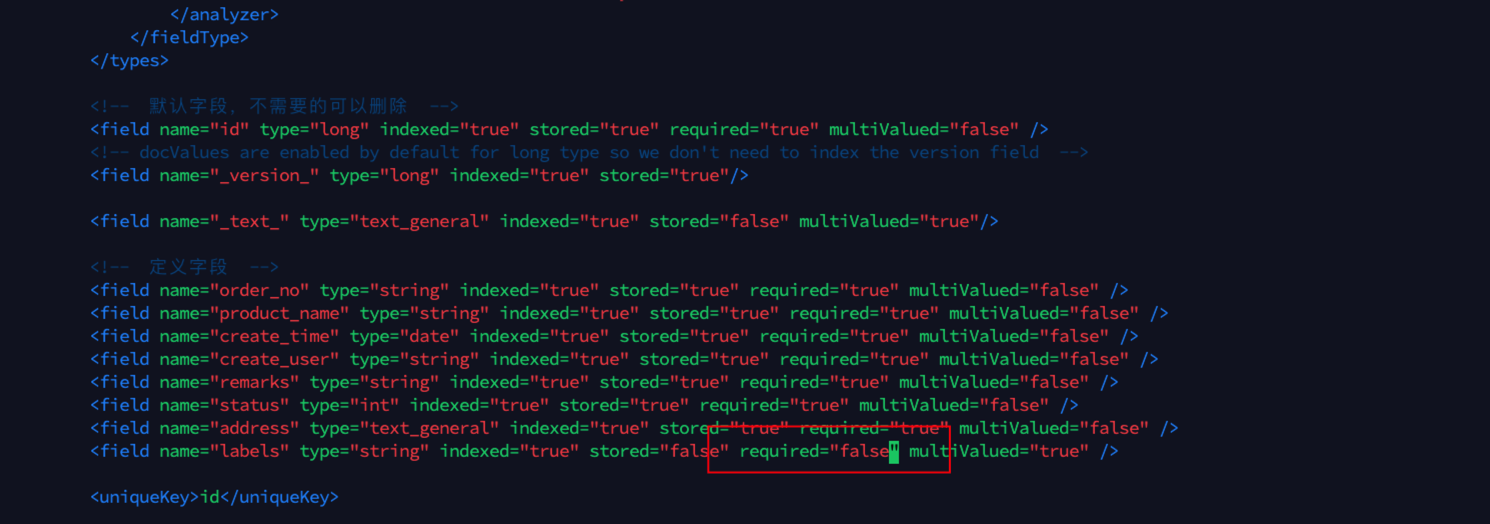
修改完重启solr,再重新同步即可
2、 Could not write property file
solr-admin中查看Logging,发现报错DocBuilder Could not write property file
查看详细的服务日志
bash
tail -500f /data/solr/server/logs/solr.log通过日志可以看到是FileNotFoundException: /data/solr/server/solr/orders/conf/dataimport.properties
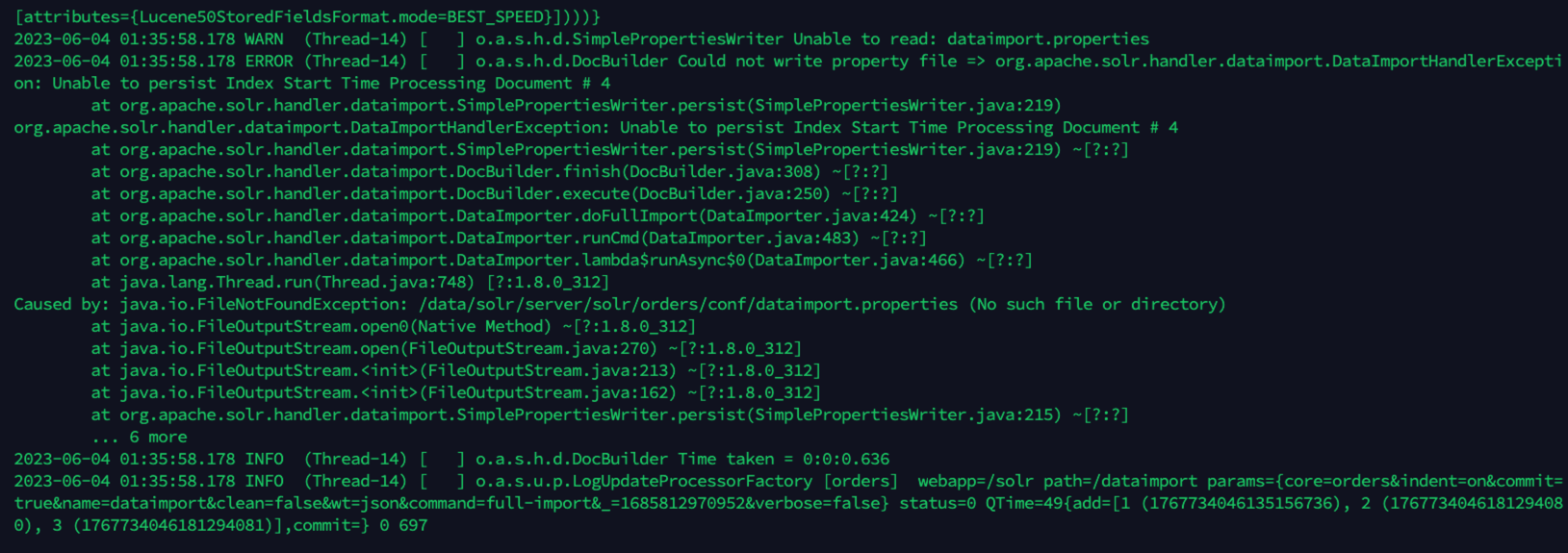
dataimport.properties 文件未找到,我们创建一个即可
bash
mkdir -p /data/solr/server/solr/orders/conf/
touch /data/solr/server/solr/orders/conf/dataimport.properties重启solr即可
mysql同步solr的核心在于配置文件的书写,当发现有错误时,可以通过服务端日志排查具体错误
4. 关于IK分词器插件安装
单机部署
单机可以选用classes方式安装和jar包安装,这里选用的是jar包安装
或:Maven Central: Search (sonatype.com)
以:Maven Central为例
进入图上两个对应的连接,点击Version,右侧点击Browse下载合适自己的分词器
然后将两个jar包放入solr目录下的:server/solr-webapp/webapp/WEB-INF/lib/目录内,修改对应核心下conf目录内的managed-schema文件,在与<fieldType name=开头的同级标签,将以下内容插入
xml
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>然后在managed-schema文件对应的字段里使用即可
xml
<uniqueKey>id</uniqueKey>
<field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/>
<field name="dzid" type="text_ik" indexed="false" stored="true"/>
<field name="dzjb" type="string" indexed="true" stored="true"/>
<field name="dzmc" type="string" indexed="true" stored="true"/>
<field name="dzjc" type="string" indexed="true" stored="true"/>然后在核心处full-import、clean、Execute。执行完查询不报错即可
SolrCloud
SolrCloud参考:https://github.com/magese/ik-analyzer-solr/blob/master/README-CLOUD.md