Appearance
Hadoop完全分布式集群环境搭建
一、集群规划
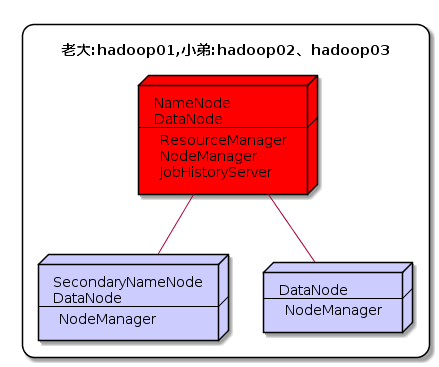
这里搭建一个 3 节点的 Hadoop 集群,其中三台主机均部署 DataNode 和 NodeManager 服务,但其中 hadoop02 上部署 SecondaryNameNode服务,hadoop01 上部署 NameNode 、 ResourceManager 和JobHistoryServer 服务。
节点ip分配情况如下:
hostname | ip
hadoop01 | 192.168.10.1
hadoop02 | 192.168.10.2
hadoop03 | 192.168.10.3二、前置条件
Hadoop 的运行依赖 JDK,需要预先安装
三、集群配置
3.1 主节点基础网络配置
- 固定IP地址
- 配置主机名
- 关闭防火墙
3.2 配置映射
配置 ip 地址和主机名映射:
bash
$ vi /etc/hosts
# 文件末尾增加
192.168.10.1 hadoop01
192.168.10.2 hadoop02
192.168.10.3 hadoop033.3 根据主节点hadoop01克隆两份系统
将hadoop01先关机,然后鼠标右击管理->克隆->创建完整克隆->填写名称、选择存放位置即可
3.4 修改各个从节点网络配置
修改IP地址和主机名
bash
$ vi /etc/sysconfig/network-scripts/ifcfg-ens33
#将原来的192.168.10.1改为192.168.10.2
#重启网络服务生效
$ systemctl restart networkIP修改完成后,使用Shell工具进行连接,之后再进行主机名的修改
bash
$ hostnamectl set-hostname hadoop02
$ vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop02
$ vi /etc/hostname
#将原来的hadoop01改为hadoop02退出当前Shell连接,再次登录查看是否配置成功
3.5 配置主从节点免密登录
3.5.1 生成密匙
在每台主机上使用 ssh-keygen 命令生成公钥私钥对:
bash
$ ssh-keygen -t rsa -C ""3.5.2 复制公钥
将 hadoop01 的公钥写到本机和远程机器的 ~/ .ssh/authorized_keys 文件中(另外两台机器上需要做同样的动作):
bash
$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop01
$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop02
$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop033.5.3 验证免密登录
bash
ssh hadoop01
ssh hadoop02
ssh hadoop033.6 同步集群时间
关于时间可以采用date -s "2024-11-24 11:25:20"或ntpdate -u ntp.api.bz进行设置,但我们一般会采用单独设置一台时间服务器,让其它所有节点与时间服务器的时间进行同步。
3.6.1 配置时间服务器(hadoop02)
1. 检查ntp包是否安装
bash
$ rpm -qa | grep ntp
ntpdate-4.2.6p5-29.el7.centos.x86_64
ntp-4.2.6p5-29.el7.centos.x86_64没有安装的话,执行以下命令进行安装:
bash
$ yum -y install ntp2. 设置时间配置文件
bash
$ vi /etc/ntp.conf
#修改一(设置本地网络上的主机不受限制)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap 为
restrict 192.168.239.0 mask 255.255.255.0 nomodify notrap
#修改二(添加默认的一个内部时钟数据,使用它为局域网用户提供服务)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
#修改三(设置为不采用公共的服务器)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
# 为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst3. 设置BIOS与系统时间同步
bash
$ vi /etc/sysconfig/ntpd
#增加如下内容(让硬件时间与系统时间一起同步)
OPTIONS="-u ntp:ntp -p /var/run/ntpd.pid -g"
SYNC_HWCLOCK=yes4. 启动ntp服务并测试
bash
$ systemctl start ntpd
$ systemctl status ntpd
#设置ntp服务开机自启
$ systemctl enable ntpd.service
#测试
$ ntpstat
synchronised to local net (127.127.1.0) at stratum 11
time correct to within 3948 ms
polling server every 64 s
$ ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
*LOCAL(0) .LOCL. 10 l 26 64 3 0.000 0.000 0.0003.6.2 其它节点与时间服务器同步时间
先关闭非时间服务器节点的ntpd服务systemctl stop ntpd
1. 手动同步
bash
$ ntpdate hadoop02
24 Nov 11:25:13 ntpdate[2878]: step time server 192.168.239.125 offset 24520304.363894 sec
$ date
2024年 11月 24日 星期二 11:25:20 CST2. 定时同步
在其他机器配置10分钟与时间服务器同步一次
bash
$ vi /etc/crontab
编写定时任务如下:
*/1 * * * * /usr/sbin/ntpdate hadoop02
#加载任务,使之生效
$ crontab /etc/crontab修改时间服务器时间
bash
$ date -s "2024-11-24 11:24:11"十分钟后查看机器是否与时间服务器同步
bash
$ date
ps:测试的时候可以将10分钟调整为1分钟,节省时间3.7 修改主节点配置文件
先创建好所需目录
bash
$ mkdir -p /data/hadoop/tmp
$ mkdir -p /data/hadoop/dfs/namenode_data
$ mkdir -p /data/hadoop/dfs/datanode_data
$ mkdir -p /data/hadoop/checkpoint/dfs/cname1. hadoop-env.sh
bash
#25行 export JAVA_HOME
export JAVA_HOME=/data/jdk
#33行 export HADOOP_CONF_DIR
export HADOOP_CONF_DIR=/data/hadoop/etc/hadoop2. core-site.xml
xml
<configuration>
<property>
<!--用来指定hdfs的老大,namenode的地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<name>hadoop.tmp.dir</name>
<value>file:///data/hadoop/tmp</value>
</property>
<property>
<!--设置缓存大小,默认4kb-->
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
</configuration>3. hdfs-site.xml
xml
<configuration>
<property>
<!--数据块默认大小128M-->
<name>dfs.block.size</name>
<value>134217728</value>
</property>
<property>
<!--副本数量,不配置的话默认为3-->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!--定点检查-->
<name>fs.checkpoint.dir</name>
<value>file:///data/hadoop/checkpoint/dfs/cname</value>
</property>
<property>
<!--namenode节点数据(元数据)的存放位置-->
<name>dfs.name.dir</name>
<value>file:///data/hadoop/dfs/namenode_data</value>
</property>
<property>
<!--datanode节点数据(元数据)的存放位置-->
<name>dfs.data.dir</name>
<value>file:///data/hadoop/dfs/datanode_data</value>
</property>
<property>
<!--指定secondarynamenode的web地址-->
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
</property>
<property>
<!--hdfs文件操作权限,false为不验证-->
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>4. mapred-site.xml
xml
<configuration>
<property>
<!--指定mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--配置任务历史服务器IPC-->
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<property>
<!--配置任务历史服务器web-UI地址-->
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
</configuration>5. yarn-site.xml
xml
<configuration>
<property>
<!--指定yarn的老大resourcemanager的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop01:8088</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop01:8033</value>
</property>
<property>
<!--NodeManager获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--开启日志聚集功能-->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!--配置日志保留7天-->
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>6. master
在当前配置文件目录内是不存在master文件的,我们使用vi写入内容到master内保存即可
bash
$ vi master
hadoop017. slaves
配置所有从属节点的主机名或 IP 地址,每行一个。所有从属节点上的 DataNode 服务和 NodeManager 服务都会被启动。
bash
hadoop01
hadoop02
hadoop033.8 分发程序
将 Hadoop 安装包分发到其他两台服务器,分发后建议在这两台服务器上也配置一下 Hadoop 的环境变量。
bash
# 将安装包分发到hadoop02
$ scp -r /data/hadoop/ root@hadoop02:/data/
# 将安装包分发到hadoop03
$ scp -r /data/hadoop/ root@hadoop03:/data/3.9 初始化
bash
$ hdfs namenode -format四、启动集群
在 hadoop01 上启动 Hadoop集群。此时 hadoop02 和 hadoop03 上的相关服务也会被启动:
bash
# 启动dfs服务
$ start-dfs.sh
# 启动yarn服务
$ start-yarn.sh
# 启动任务历史服务器
$ mr-jobhistory-daemon.sh start historyserver4.1 查看集群
在每台服务器上使用 jps 命令查看服务进程,或直接进入 Web-UI 界面进行查看,端口为 50070。可以看到此时有三个可用的 Datanode:
bash
$ jps
13664 ResourceManager
13250 NameNode
14101 JobHistoryServer
14135 Jps
13387 DataNode
13773 NodeManager
$ jps
9793 SecondaryNameNode
9685 DataNode
9898 NodeManager
9930 Jps
$ jps
9880 DataNode
10024 NodeManager
10056 Jps点击 Live Nodes 进入,可以看到每个 DataNode 的详细情况,接着可以查看 Yarn 的情况,端口号为 8088